聊聊chatbot那些事
1. 生活中的chatbot
现在社会,随着AI的迅猛发展,各种新技术层出不穷,大大改变了我们的生活,其中,有很多技术已经走入了我们的日常生活,比如CV领域的人脸识别 ,NLP 领域的智能助手等。本次,我们就来聊聊智能助手中会涉及到的技术,也就是chatbot。
chatbot,其实是有很多分类的,目前,最常见的是把它分为一下几类:
-
Chit-Chat-oriented Dialogue Systems: 闲聊型对话机器人,产生有意义且丰富的回复。
-
Task-oriented: 任务驱动类,我们日常生活中常用的智能助手就是这类。
这两类其实技术方面是互通的。虽然深度学习以及强化学习等技术发展迅速,不过,在目前的智能助手中,占据主要地位的还是基于规则的,智能助手对话经过预定义的规则(关键词、if-else、机器学习方法等)处理,然后执行相应的操作,产生回复。这种方式虽然生成的对话质量较高,不过,缺点是规则的定义,系统越复杂规则也越多,而且其无法理解人类语言,也无法生成有意义的自然语言对话。处在比较浅层的阶段(最重要的是,这种方式并不好玩!!!),而基于生成式的chatbot,则可以生成更加丰富、有意义、特别的对话响应。但是,该类bot存在许多问题,比如沉闷的回应、agent没有一个固定的风格、多轮对话等等。不过,尽管 有问题,后续还是可以提高的嘛,对于我们AI工程师来说,我们还是希望能运用上我们掌握技术 ,去做一个生成式的chatbot,这样,才有成就感啊。
2. 基于seq2seq的chatbot
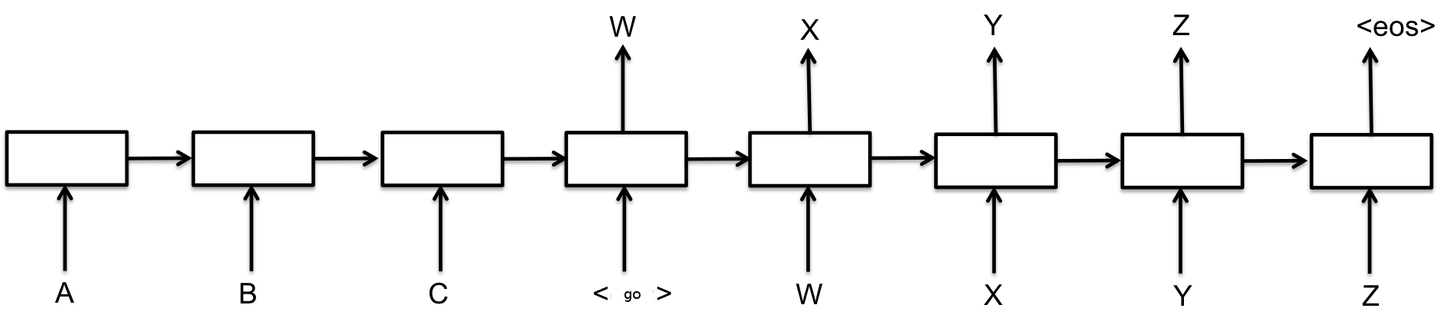
图1 seq2seq结构
seq2seq应该是序列到序列模型中最经典的了,基础的seq2seq模型包含了三个部分,即Encoder、Decoder以及连接两者的中间状态向量,Encoder通过学习输入,将其编码成一个固定大小的状态向量S,继而将S传给Decoder,Decoder再通过对状态向量S的学习来进行输出。
seq2seq的两个基本结构都是一类rnn单元,而rnn天然适合变长序列任务,不过,最初的rnn饱受梯度弥散的困扰,因而,后续发展出的rnn通过状态的引入来减缓了这种现象,目前,最常用的rnn结构便是lstm以及gru。
3. 基于attention-seq2seq的chatbot
近年来,深度学习中的Attention机制的引入,提高了各种模型的成功率,在sota的模型中,Attention仍然是无处不在的组成部分。因此,非常有必要关注Attention机制。不过,在这篇文章中,我们主要关注两种最经典的attention结构,即:
这两种attention虽然年代久远,不过,对于我们理解attention的作用还是很有裨益的。
3.1 attention为何物?
当我们看到 “Attention “这个词时,脑海里想到的意思便是将你的注意力引导到某件事情上,并给予更大的注意。而深度学习中的Attention机制就是基于这种引导你的注意力的概念,它在处理数据时,会对某些因素给予更大的关注。
广义来讲,attention是网络结构的一个部件,它负责管理和量化下面两种相互依赖关系:
- 输入与输出元素之间,即General Attention
- 输入元素之间,即Self-Attention
attention为何有效呢 ?回到图1,我们知道seq2seq的encoder是把整个句子压缩成了一个高维向量,而句子是变化多端的,一个长句子被压缩一个向量,会存在比较大的信息缺失现象,更合理的做法是,针对句子层面以及单词层面同时考量,这样能大大缓解这种信息缺失,提高模型的效果,举个例子来说,在做机器翻译的时候,输入句子为:“chatbot is interesting!”,翻译结果为“聊天机器人很有趣”, 那么,在翻译“聊天机器人”这个单词的时候,就会对“chatbot”这个单词给予更大的关注,从而提高了翻译的准确性。
3.2 Bahdanau Attention
这个attention提出于2014年,就今天来说是个相当古老的模型了,不过,也因为它早,所以显出其经典性。

图2 Bahdanau Attention
这种Attention,通常被称为Additive Attention。该Attention的提出旨在通过将解码器与相关输入句子对齐,并实现Attention,来改进机器翻译中的序列到序列模型。论文中应用Attention的整个步骤如图:

当时的经典模型,随着时间的流逝,看起来也不在多高大上了,不得不感叹技术的发展啊!
3.3 Luong Attention
该类Attention通常被称为 Multiplicative Attention,是建立在Bahdanau提出的注意机制之上。Luong Attention和Bahdanau Attention的两个主要区别在于:
- 对齐得分的计算方式
- attention机制被引入decoder的位置

这两种Attention的score的计算方式如下:
Bahdanau Attention:
\[score_{alignment} = W_{combined} \cdot tanh(W_{decoder} \cdot H_{decoder} + W_{encoder} \cdot H_{encoder})\]Luong Attention:
-
dot
\[score_{alignment} = H_{encoder} \cdot H_{decoder}\] -
general
\[score_{alignment} = W(H_{encoder} \cdot H_{decoder})\] -
concat
4. 来做一个自己的chatbot吧!
讲了那么多无聊的理论,是时候展示一些真正的技术了,毕竟,talk is cheap嘛,现在,让我们开始自己的表演!
4.1 数据集
万里之行,始于足下。要想有个比较好的bot,语料是必不可少的,现在有很多开源的chatbot数据集,其质量也有好有坏,要注意甄别。因为我想做个能自然对话的机器人,所以我选择了传闻中的小黄鸡数据集,不过其数据量很大,大约有45w个对话的样子,这么大的量级下,要训练出一个收敛的效果,除非你的计算资源非常强大,要不然会很费时,所以,为了简便起见,我从中抽取了4w条对话用来做训练,在双gpu 24G显存下,设置batch size为400,一个晚上基本可以跑完。
4.2 评价指标
所谓模型好不好,用指标说话,不过,在chatbot领域,这个就比较尴尬,因为chatbot领域不存在很适用的评价指标,这是因为chatbot的聊天内容是很开放的,对于一个query,可能存在非常多的合适的answer,而且,这种多变的answer也是我们希望的,这样显得我们的模型有非常好的多样性。目前,chatbot常用的指标多是从机器翻译,摘要生成等领域提出来的,其常用的指标为PPL(至少我是这样的…)
不过,指标虽多,并没有一个可以很好的解决对话系统的问题,就像“How NOT To Evaluate Your Dialogue System”论文中说到的那样,当下的这些评价指标都跟人工评价成弱相关或者完全没有关系,相关程度跟具体的数据集有关。所以,要想知道chatbot究竟好不好,最终是离不开人工评价的,这也是为何目前的成熟的智能助手都是基于规则的原因。
4.3 模型搞起
聊完了数据集和评价指标,就到了激动人心的时刻,让我们开始搭建我们的模型吧。
1)数据预处理
预处理属于流程化的东西,所幸也有流程化的包,我们这里采用torchtext包来处理数据:
# 设置field,用来负责处理指定列的文本数据
SRC_TEXT = Field(sequential=True, init_token=SOS_TOKEN, eos_token=EOS_TOKEN, tokenize=tokenize,include_lengths=True)
# src和target使用同样的field,因为它们处理的都是中文文本,如果是翻译任务则需要针对不同的语言构造不同的field
train_data, val_data = TabularDataset.splits(
path='./datasets/', train='small_train.tsv',
validation='demo.tsv', format='tsv',skip_header=True,
fields=[('src', SRC_TEXT), ('target', SRC_TEXT)])
# SRC_TEXT会用它负责的列的文本构造词典,上面就是用src和target列
SRC_TEXT.build_vocab(train_data)
2)encoder构造
没啥说的,注意pack_padded_sequence的使用。
class EncoderRNN(nn.Module):
def __init__(self, input_size, hidden_size, n_layers=1, dropout=0.1):
super(EncoderRNN, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.n_layers = n_layers
self.dropout = dropout
self.embedding = nn.Embedding(input_size, hidden_size)
self.gru = nn.GRU(hidden_size, hidden_size, n_layers, bidirectional=True, dropout=self.dropout)
def forward(self, input_seqs, input_lengths, hidden=None):
total_length = input_seqs.size()[0]
embedded = self.embedding(input_seqs)
packed = torch.nn.utils.rnn.pack_padded_sequence(embedded, input_lengths)
self.gru.flatten_parameters()
outputs, hidden = self.gru(packed, hidden)
# unpack (back to padded)
outputs, output_lengths = torch.nn.utils.rnn.pad_packed_sequence(outputs, total_length=total_length)
outputs = outputs[:, :, :self.hidden_size] + outputs[:, :, self.hidden_size:] # Sum bidirectional outputs
return outputs, hidden
3)attention的实现,该实现可以实现batch计算
class Attn(nn.Module):
def __init__(self, method, hidden_size):
super(Attn, self).__init__()
self.method = method
self.hidden_size = hidden_size
if self.method == 'general':
self.attn = nn.Linear(self.hidden_size, hidden_size)
elif self.method == 'concat':
self.attn = nn.Linear(self.hidden_size * 2, hidden_size)
self.v = nn.Parameter(torch.FloatTensor(1, hidden_size))
torch.nn.init.xavier_normal_(self.v)
def forward(self, hidden, encoder_outputs):
# Create variable to store attention energies
attn_energies = self.score(hidden, encoder_outputs)
# Normalize energies to weights in range 0 to 1, resize to 1 x B x S
return F.softmax(attn_energies, dim=-1)
def score(self, hidden, encoder_output):
'''
compute an attention score, 注意,多层的gru只有最底层需要计算attention score
:param hidden: (n_layers, batch_size,hidden_dim) deocder的hidden
:param encoder_output: max_len x batch_size x hidden_size
:param decoder_output: 1 * batch * hidden_size
:return: a score (batch_size,1, max_len)
'''
if self.method == 'dot':
energy = hidden[0].unsqueeze(1).bmm(encoder_output.permute(1, 2, 0)) # B 1 D * B D S = B 1 S
return energy
elif self.method == 'general':
max_len, batch_size, _ = encoder_output.size()
encoder_output = encoder_output.view(batch_size * max_len, -1)
encoder_output = self.attn(encoder_output)
encoder_output = encoder_output.view(max_len, batch_size, -1).transpose(0, 1) # S B D->B S D
energy = hidden[0].unsqueeze(1).bmm(encoder_output.transpose(1, 2)) # B 1 D * B D S = B 1 S
return energy
elif self.method == 'concat':
hidden = hidden[0].unsqueeze(1).repeat(1, encoder_output.size()[0], 1) # B max_len hidden_dim
concated = torch.cat((hidden, encoder_output.transpose(0, 1)), dim=-1).view((-1, hidden.size()[-1] * 2))
energy = self.attn(concated)
energy = energy.view(hidden.size())
energy = energy.transpose(1, 2)
return self.v.matmul(energy) # B ! D * B D S = B 1 S
4)decoder
class LuongAttnDecoderRNN(nn.Module):
def __init__(self, attn_model, hidden_size, output_size, n_layers=1, dropout=0.1):
super(LuongAttnDecoderRNN, self).__init__()
# Keep for reference
self.attn_model = attn_model
self.hidden_size = hidden_size
self.output_size = output_size
self.n_layers = n_layers
self.dropout = dropout
# Define layers
self.embedding = nn.Embedding(output_size, hidden_size)
self.gru = nn.GRU(hidden_size, hidden_size, n_layers,dropout=dropout)
self.embedding_dropout = nn.Dropout(dropout)
self.concat = nn.Linear(hidden_size * 2, hidden_size)
self.out = nn.Linear(hidden_size, output_size)
# Choose attention model
if attn_model != 'none':
self.attn = Attn(attn_model, hidden_size)
def forward(self, input_seq, context, encoder_outputs):
# Get the embedding of the current input word (last output word)
input_seq = input_seq.unsqueeze(0)
embedded = self.embedding(input_seq)
embedded = self.embedding_dropout(embedded)
self.gru.flatten_parameters()
rnn_output, hidden = self.gru(embedded, context)
# Calculate attention from current RNN state and all encoder outputs;
# apply to encoder outputs to get weighted average
attn_weights = self.attn(hidden, encoder_outputs) # B 1 S
context = attn_weights.bmm(encoder_outputs.transpose(1, 0)) # B 1 H
# Attentional vector using the RNN hidden state and context vector
# concatenated together (Luong eq. 5)
context = context.transpose(0, 1) # 1 x B x N
concat_input = torch.cat((rnn_output, context), -1).squeeze(0) # B × 2*N
concat_output = torch.tanh(self.concat(concat_input))
# Finally predict next token (Luong eq. 6, without softmax)
output = self.out(concat_output)
rnn_output = self.out(rnn_output.squeeze(0))
return output, hidden, attn_weights
5) 整合成seq2seq模型
class Seq2Seq(nn.Module):
def __init__(self, vocabs, hidden_size, n_layers, dropout, max_len, attn_model='concat',
sos=0, eos=0, **kwargs):
super(Seq2Seq, self).__init__()
encoder = EncoderRNN(len(vocabs['src_vocab']), hidden_size, n_layers, dropout)
decoder = LuongAttnDecoderRNN(attn_model, hidden_size, len(vocabs['tgt_vocab']), n_layers, dropout)
self.encoder = encoder
self.decoder = decoder
self.sos = sos
self.eos = eos
self.max_len = max_len
assert encoder.hidden_size == decoder.hidden_size, \
"Hidden dimensions of encoder and decoder must be equal!"
assert encoder.n_layers == decoder.n_layers, \
"Encoder and decoder must have equal number of layers!"
def forward(self, src, tgt=None, src_lengths=None, tgt_lengths=None, teacher_forcing_ratio=1):
if src_lengths is not None and len(src.size())>1:
src_lengths = src_lengths.squeeze(0)
encoder_outputs, encoder_hidden = self.encoder(src, src_lengths, None)
# Prepare input and output variables
if tgt is not None:
decoder_input = tgt[0, :]
else:
this_batch_size = src.size()[1]
decoder_input = torch.LongTensor([self.sos] * this_batch_size).cuda()
# 对于多层的gru,要排除掉后向的hidden,只使用前向的hidden
decoder_hidden = encoder_hidden[-self.decoder.n_layers * 2::2].contiguous() # Use last (forward) hidden state
max_target_length = tgt.size()[0] if tgt is not None else self.max_len
decoder_outputs = []
# Run through decoder one time step at a time
use_teacher_forcing = random.random() < teacher_forcing_ratio
for t in range(max_target_length):
decoder_output, decoder_hidden, decoder_attn = self.decoder(
decoder_input, decoder_hidden, encoder_outputs
)
decoder_outputs.append(decoder_output)
decoder_input = tgt[t] if use_teacher_forcing else decoder_output.argmax(-1)
return torch.stack(decoder_outputs)