自然语言处理中的embeddings
1. 背景
自2010年代初以来,嵌入一直是自然语言处理(NLP)的主流热词之一。将信息编码成低维向量表示,在现代机器学习算法中很容易集成,这在NLP的发展中起到了核心作用。嵌入技术最初集中在单词上,但很快就开始将注意力转移到其他形式上:从图结构,如知识库,到其他类型的文本内容,如句子和文档。
接下来,我们会从最初的one-hot开始,探索embddings在nlp领域的发展。
2. 概览
在embeddings技术出现以前,nlp领域应用较多的是以one-hot为主的简单representation。这类技术可以根据需要对单词索引处的value做不同的处理,比如直接用1表示,用词频(term frequency),TF-IDF(term frequency–inverse document frequency)等等,这样技术在nlp的发展历程中发挥了重大的作用,不过,其也有几方面的问题:
- 无法结合丰富的语义信息,对于相似的单词,比如“table”,“desk”,具有完全不同的表示,无法定义similarity概念。
- 这类表示的向量长度取决于字典的长度,对于一种语言来说,其常用词通常会有成百上千个,要想表示更具备通用性,那么字典的长度就会达到很大,带来的后果就是巨大的空间消耗与计算复杂度,这么长的特征也很难直接嵌入到其他的任务中。
这类问题随着以word2vec为代表的embeddings技术的出现而得到了改变,这类新技术引入了语义空间的概念,它们不同于one-hot类型的表示的地方在于,其建模是无序的,也就是说他们不再建模每个单词在词典中 的位置信息,而是直接针对该单词的语义进行建模,这时候也有位置的概念,不过位置的作用仅限于进行索引来获得单词的语义向量。
这就带来了很大的好处:
- 由于每个单词有自己的词义向量,因而可以很自然的引入similarity的概念,可以通过各种距离函数度量两个向量的相似度,从而判断单词的similarity。
- 语义向量可以大大缩短,不在局限于字典的长度,哪怕字典很大,也可以用一个低维的向量表示单词的语义向量。
虽然embeddings技术有非常大的优势,不过其也有一些局限之处,其中一个很大的限制就是词的动态属性,比如,mouse一词在不同的语境下可以代表老鼠,也可以代表鼠标,而语义向量在训练完成后便是静态的了。
当然,针对这类问题也有一些相关研究了,比如最新的语境化表示,目的是解决词嵌入的静态性质,让嵌入物根据它出现的上下文进行自我调整。与传统的单词嵌入不同,这些模型的输入不是孤立的单词,而是单词及其上下文。这类技术也处在蓬勃发展之中。
3. Word Embeddings
3.1 count-based模型
传统的构建VSM(vector space model)的方法主要是基于词频,因此,这种方法通常被称为基于计数的方法。广义上讲,基于计数的模型的总主题是基于词频构建矩阵。
这类模型可以分为如下三类:
-
Term-document
在这个矩阵中,行对应单词,列对应文档。每一个单元格表示特定词在特定文档中的频率,以衡量文档对的语义相似性。具有相似数字模式(相似列)的两个文档被认为是具有相似主题的文档。术语term-document模型是以document为中心的,因此,它通常用于文档检索、分类或类似的基于文档的目的。这种矩阵中,每一行的向量就对应着该单词的embedding
-
Word-context
与term-document矩阵侧重于文档表示不同,word-context矩阵旨在表示词。Deerwester等人[1990]首次提出使用这种矩阵来测量词的相似性。比较重要的是,他们将上下文的概念从文档扩展到了更灵活的定义,允许广泛的可能性,从相邻的词到词的窗口,到语法依赖性或词性偏好,再到整个文档。word-context矩阵是最广泛的建模形式,可以实现许多应用和任务,如词的相似度测量、词义辨别、语义角色标注和查询扩展。这类向量类似于term-document,不过其行是针对context的,这显然相比于term-document是一种更高阶的相似度。
-
Pair-pattern
在这个矩阵中,行对应词对,列是两者出现过的模式。Lin和Pantel[2001]用它来寻找模式的相似性,如 “X是Y的作者 “和 “Y是X写的”。该矩阵适用于测量关系相似性:成对词语之间语义关系的相似性,如 “linux:grep “和 “windows:findstr”。Lin和Pantel[2001]首次提出了扩展distributional hypothesis:与相似对(上下文)共同出现的模式往往具有相似的含义。
3.1.1 点阵互信息(POINTWISE MUTUAL INFORMATION)
原始频率不能提供可靠的关联度。像 “the “这样的stop word可以经常与一个特定的词共存,但这种共存不一定对应于语义关系,因为它不是辨别性的。比较理想的是,有一个能够结合共现的信息性的测量方法。正点互信息(Positive Pointwise Mutual Information,PPMI)就是这样一种测量方法。PMI通过两个词的单个频率来归一化两个词的共现的重要性。
其计算公式为: \(PMI(w_{1},w_{2}) = log_{2}\frac{P(w_{1},w_{2})}{P(w_{1})P(w_{2})}\) 其中,$P(x)$是词x的词频,PMI会检查$w_{1}$和$w_{2}$的共现次数而不仅仅是他们单独的词频。stop word的P值较高,这导致整体PMI值降低。PMI值的范围可以从- inf到+ inf 。负值表示共同出现的可能性比偶然发生的可能性小。考虑到这些关联是基于高度稀疏的数据计算出来的,而且它们不容易被解释(很难定义两个词非常 “不相关 “是什么意思),我们通常会忽略负值,用0代替,因此,该方法被称为正PMI(PPMI)。
3.1.2 降维
word-context建模是计算基于计数的词表征的最广泛的方法。通常,取与目标词共存的词作为其上下文。因此,这个矩阵中的列数等于词汇中的词数(即语料库中唯一的词)。这个数字很容易达到几十万甚至几百万,这对计算和存储来说显然是个瓶颈。为了规避这个限制,通常会对VSM使用降维技术。
减少维度可以通过简单地放弃那些信息量较少或重要的上下文(即列)(例如,频繁的功能词)来获得。这可以使用特征选择技术来完成。但是,我们也可以通过合并或将多个列合并成较少的新列来重新划分维度,这可以通过奇异值分解(SVD)来实现。
3.2 预测模型(PREDICTIVE MODELS)
这种模型便是目前火热的深度学习模型的拿手好戏了。在过去的十年里,伴随着深度学习的发展,基于神经网络的表示方法(embeddings)几乎完全取代了传统的基于计数的模型,并在该领域占据了主导地位。这种模型的首要功臣便是Word2vec。
Word2vec是基于一个简单但有效的前馈神经架构,它以语言建模为目标进行训练。共有两种不同但相关的Word2vec模型。即连续词袋模型(continuous Bag-Of-Words(CBOW))和Skip-gram。CBOW模型的目的是利用周围的上下文来预测当前的单词,最小化以下损失函数: \(E = -log(p(\vec {w_{t}}|\vec {W_{t}}))\) 其中,$w_{t}$是目标词,$W_{t} = w_{t-n},…,w_{t},w_{t+n}$代表上下文中的单词序列。Skip-gram模型类似于CBOW模型,不过不同之处在于这个模型的目标是在给定目标词的情况下预测周围的单词,而不是直接预测该目标词本身。
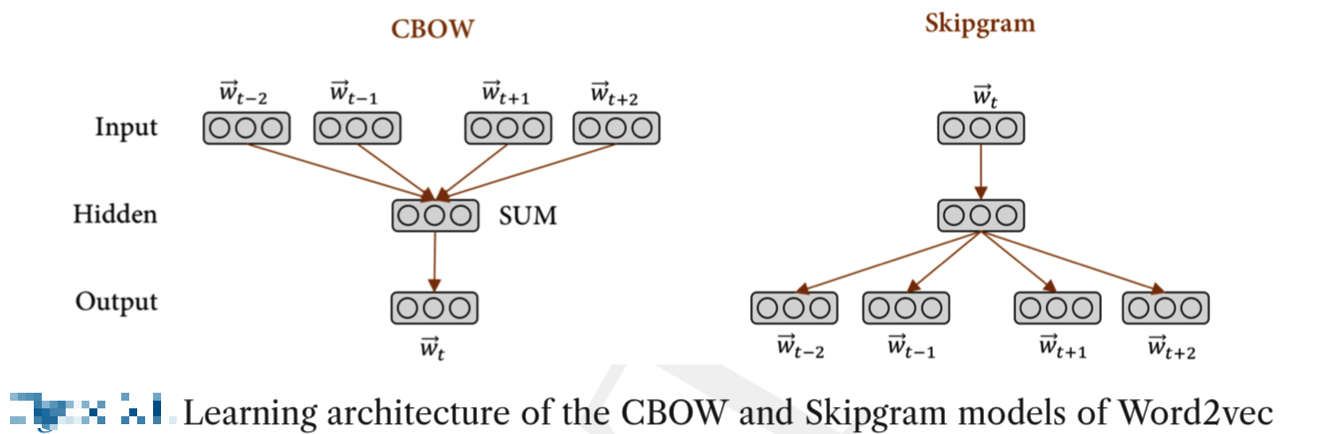
上图便是是Word2vec的CBOW和Skip-gram模型的总体架构简化图。该架构由输入层、隐藏层和输出层组成。输入层的长度为词典的大小,并将上下文编码为给定目标词的周围单词的one-hot向量表示组合(现在的实现中已经不这么做了,而是为每个word分配一个vector,用该vector代表该word的表示)。输出层具有与输入层相同的大小,在训练过程中为目标词的one-hot向量,通过soft Max处理后得到目标词的索引。
由于输出层的大小为字典的大小,而字典通常非常大,所以直接进行softmax的话会非常耗时,针对这个问题,word2vec使用了hierarchical softmax和负采样技术来优化训练。
除了word2vec,还有个很重要的词向量:GloVe(Global Vectors for Word Representation),它是一个基于全局词频统计(count-based & overall statistics)的词表征(word representation)工具,它可以把一个单词表达成一个由实数组成的向量,这些向量捕捉到了单词之间一些语义特性,比如相似性(similarity)、类比性(analogy)等。
GloVe通过如下三步实现:
-
根据语料库构建一个共现矩阵(Co-ocurrence Matrix)$X$,矩阵中的每个元素$X_{ij}$代表单词i和上下文单词j在特定大小的上下文窗口(context window)内共同出现的次数。直观上这个次数的最小单位应该是1,不过GloVe不这么认为,它根据这两个单词在上下文窗口中的距离$d$,构造了一个衰减系数(decreasing weighting): $decay=1/d$用于计算权重,所以距离越远的两个单词所占总计数(total count)的权重越小。
-
构建词向量和共现矩阵之间的近似关系: \(w_{i}^{T}\tilde w_{j}+b_{i}+\tilde b_{j}=log(X_{ij})\) 其中,$w_{i}^{T}$和$\tilde w_{j}$就是要最终求解的词向量;$b_{i}$和$\tilde b_{j}$是两个词向量之间的bias term。
该近似关系的构造需要一些考虑,假定:
(1)$X_{ij}$表示单词j出现在单词i的上下文中的次数
(2) $X_{i}$表示单词i的上下文中所有单词出现的总次数,即$X_{i}=\sum^{k}X_{ik}$
(3) $P_{ij}=P(j i)=X_{ij}/X_{i}$,即单词j出现在单词i的上下文中的概率 通过统计得到一个词频样本列表:

从最后一列可以看出两个单词i和j相对于单词k哪个更相关,以图中例子说明,ice与solid更相关,而steam与solid明显不相关,所以$P(solid|ice)/P(solid|steam)$就远大于1,同样的gas与steam更相关,而ice与gas更不相关,所以$P(gas|ice)/P(gas|steam)$就远小于1;当与k都相关(比如water)或者都没有关(比如fashion)的时候,两者的比例就接近1.这个观察可以告诉我们一个事实:通过概率的比例而不是概率本身去学习词向量可能是一个更恰当的方法。那么,加入已经有了词向量,如果可以用词向量$v_{i},v_{j},v_{k}$计算得到他们的相关比例,满足上面观察到的性质,那么词向量便于共现矩阵具有很好的一致性,可以假定计算相关比例的函数g,并应该尽量满足如下的公式: \(\frac {P_{i,k}}{P_{j,k}} = g(v_{i},v_{j},v_{k})\) 如果可以得到g,那么显然可以很自然的构造代价函数: \(J=\sum_{i,j,k}^{N}(\frac{P_{i,k}}{P_{j,k}}-g(v_{i},v_{j},v_{k}))^2\) 如何构造g呢?
(1) 要度量$v_{i},v_{j}$的关系,$v_{i}-v_{j}$是个合理的考虑
(2) $v_{i},v_{j},v_{k}$均是向量,要转化成标量,可以使用$(v_{i}-v_{j})^{T}v_{k}$
(3)上面两步处理后$\frac {P_{i,k}}{P_{j,k}} = g(v_{i},v_{j},v_{k}) \mapsto \frac {P_{i,k}}{P_{j,k}}=g((v_{i}-v_{j})^{T}v_{k}) \mapsto \frac {P_{i,k}}{P_{j,k}}=g(v_{i}^{T}v_{k}-v_{j}^{T}v_{k})$,那么,一个很自然的想法是将g设定为exp函数,从而得到:$\frac {P_{i,k}}{P_{j,k}}=\frac {exp(v_{i}^{T}v_{k})}{exp(v_{j}^{T}v_{k})}$,这便得到了公式的一致性,这时候问题就可以统一转化为求:$P_{i,j}=exp(v_{i}^{T}v_{j}) \mapsto log(P_{i,j})=v_{i}^{T}v_{k}$,而右边的公式左侧是不满足对称性而右侧满足对称性,进一步转化:$v_{i}^{T}v_{k}=log(P_{i,j})=log(X_{i,j})-log(X_{i})$,而由于$log(P_{i})$独立于k,因而使用一个bias term $b_{i}$替换掉,得到$v_{i}^{T}v_{k}+b_{i}=log(P_{i,j})$,该式同样不满足对称性,添加个$b_{j}$补救,这样处理以后便得到了公式(3).
-
现在有了优化目标,便可以训练了。构造如下的loss function: \(J = \sum_{i,j=1}^{V} f(X_{ij})(w_{i}^{T}\tilde{w_{j}} + b_i + \tilde{b_j} – \log(X_{ij}) )^2\) 这个loss function的基本形式为最简单的mean square loss,并在此基础上加了一个权重函数$f(X_{ij})$,那么这个函数起了什么作用,为什么要添加这个函数呢?我们知道在一个语料库中,肯定存在很多单词他们在一起出现的次数是很多的(frequent co-occurrences),那么我们希望:
(1)这些单词的权重要大于那些很少在一起出现的单词(rare co-occurrences),所以这个函数要是非递减函数(non-decreasing);
(2)但我们也不希望这个权重过大(overweighted),当到达一定程度之后应该不再增加;
(3)如果两个单词没有在一起出现,也就是$X_{ij}=0$,那么他们应该不参与到loss function的计算当中去,也就是$f(x)$要满足$f(0)=0$
满足以上两个条件的函数有很多,作者采用了如下形式的分段函数: $$ f(x)=\begin{equation}
\begin{cases}
(x/x_{max})^{\alpha} & \text{if} \ x < x_{max} \
1 & \text{otherwise}
\end{cases}
\end{equation} $$

论文中的所有实验$\alpha$的取值都是0.75,而$x_{max}$取值都是100.
3.3 字符嵌入(CHARACTER EMBEDDING)
OOV(out of vocabulary)问题在nlp领域非常普遍,对于这种情况,最简单的做法给OOV词赋于一个随机的embedding,不过这并不是一个好的做法,特别是该词在上下文理解和决策过程中扮演着中心词的角色。
有些研究人员提出了一种适用于英文的处理OOV的方法,鉴于许多OOV词可以是词汇中现有词的形态变化,通常可以使用形态分词器将这类词分解为组成部分,并通过扩展未见词的形态变化的语义来计算表示。例如,像 memoryless 这样的未见词可以被分解成 memory 和 less。根据memory和less的嵌入,可以为这个未见词诱导出一个嵌入,这两个成分在训练过程中出现的频率较高,所以在训练的时候出现更高。
另外,单词也可以被分解成组成子词,比如不一定具有语义的字符组。FastText就是这种方法的一个突出例子,除了出现在训练语料中的那些单词,模型也可以学到这些词的n-grams的嵌入。然后,如果碰到未见到的词,通过对其组成字符n-grams的向量表示进行平均,得到相应的嵌入。
fasttext专注于文本分类和文本向量化表示场景,和最前沿深度神经网络模型相比,它在分类精度等指标毫不逊色的情况下,把训练和推断速度降低了几个数量级!按Facebook的报告,在普通多核CPU上,10亿词的文本训练时间小于10分钟,50万句子分到31.2万类别用时小于1分钟。
大多数的词向量技术会为每个单词分配一个向量表示,而不会考虑到单词内部的结构,而这对于形态多变的语言来说是个很大的限制,因为形态多变的缘故,所以很多次会很少出现在训练语料库中,导致学习到的单词表示并不理想,所以fasttext在这方面提出了自己的解决方案,这就是考虑单词内部的字符级顺序,通过subword建模morphology,然后通过单词的character n-grams的加和来表述单词。
这样做好处也明显:
- 对于低频词生成的词向量效果会更好。因为它们的n-gram可以和其它词共享。
- 对于训练词库之外的单词,仍然可以构建它们的词向量。我们可以叠加它们的字符级n-gram向量。
以英文来说,要学习“where”的表示,在开始和结束添加两个边界符号”<”,”>”变成”
", 可以划分3-gram:{"<wh","whe","her","ere","re>"," "},添加边界符号的作用除了可以和其他符号作区分外,还有个好处,比如集合中的"her",就不同于" ",后者代表单词"her"的表达,实际使用可根据需要抽取不同的n(对于中文而言,character可以表示单个字)。最终,得到单词的n-grams集合(包含添加了边界符的词本身):$\varsigma=\left \{1,...,G\right \}$, 计算该word与其上下文中单词$w_{c}$的score的时候计算公式变成:$s=w_{word}^{T}w_{c} \mapsto s=\sum_{g \in \varsigma}z_{g}^{T}w_{c}$,其中$z_{g}$为每个n-gram的向量,每个word的向量v通过集合$\varsigma$的加和计算得到。

这为OOV嵌入提供了一个快速的解决方案,但考虑到两个词可能具有相似的n-gram构成,但在语义上是不同的,这并不是一个最佳方案。
还有一种方式就是通过引入外部语料库知识(比如WordNet)来推导出未见词的嵌入,比如从WordNet中提取了一组与OOV词语义相似的词,并将它们的嵌入结合起来,形成OOV词的嵌入。这些技术做出了一个假设,即OOV词在底层词汇资源中已经被覆盖,但这可能不一定是真的。
3.4 其他
前面介绍的方法基本都是基于文本语料库构建出来的,不过也有一种研究(NOWLEDGE-ENHANCED WORD EMBEDDINGS)试图将文本语料库中的信息与词汇资源中编码的知识结合起来。这种知识可以被用来包含文本语料库中没有的额外信息,以提高现有词向量表示的语义一致性或覆盖面。此外,还有一种使用共享的低维向量空间来建模多种语言的CROSS-LINGUAL WORD EMBEDDINGS技术,这里就不再详细介绍。
3.5 EVALUATION
本节会介绍如何评价word representations的技术,根据评估方法的不同,可以分为intrinsic和extrinsic两类:
-
内涵评估(INTRINSIC EVALUATION)
内涵评估提供了对向量空间的质量和一致性的通用评价,而与它们在下游应用中的性能无关。传统上,语义相似性(semantic similarity )特别是小的词汇单元比如word的相似性被认为是最直接的特征而收到了最多的关注。
此外,要区分相似性和相关性(relatedness)的概念。如果两个词具有许多共同的属性,就被认为是语义相似的(如 “自行车 “和 “摩托车”,”青柠 “和 “柠檬”),而只要它们具有任何语义关系,如部分-整体关系(如 “车轮 “和 “自行车”)或反义词(”日落 “和 “日出”),就被认为是语义相关的。虽然语义相近的词在技术上可以在上下文中相互替代,但相关词在同一上下文中(如文档内)共同出现较多,而不需要可替代性。
除了语义相似性外,还有一些常用的指标,比如著名的Analogy测试,该指标是embedding线性规则的体现,可以用来进行词汇对比测试,即A-B=C-D(如king – queen = man – woman)。更直观的可以通过降维来达到词向量的可视化效果,观察相似词的分布情况是否合理。
不过,内涵评估也有很大的问题,一个很大的限制就是单词相似性评估通常只考虑词的归因相似性(attributional similarity),比如两个词的属性之间的相似程度。然而,NLP中的不同任务处理的是不同的相似性概念,而相似性概念可能不一定与归因相似性相匹配。例如,用于词性标注模型的词嵌入不需要编码细粒度的语义区分,例如,对猫和老虎甚至长颈鹿有相同的表示可能不是问题。然而,对于QA系统来说,细粒度的区分,如南北方之间的区分可能是至关重要的:当被问及 “什么时候去博物馆参观最好?”时,回答 “日落前后 “和 “日出前后 “有很大的不同。
考虑到相似性概念的可变性,人们可能会预期词嵌入在不同的NLP任务中会有不同的表现。事实上,不同的研究者都表明,内涵评估协议并不总是与下流性能相关,有些研究表明,标准的词相似度基准上的性能与情感分析、隐喻检测和文本分类等任务的结果相关性较低,甚至有研究发现,词相似度性能与命名实体识别的结果之间存在负相关。
-
外延评估(EXTRINSIC EVALUATION)
外延评估旨在评估向量表示作为机器学习模型的输入特征时,在downstram NLP任务中的质量。
外延评估反映词嵌入在下游场景中的性能,但与内在评价类似,它们容易受到限制,这使得它们不足以作为评价词嵌入的唯一依据。第一个局限性在某种程度上是内涵评估和外延评估之间共有的,它来自于不同的NLP任务在性质上可能有很大的不同。事实上,词嵌入性能在不同的任务中并不一定有相关性。这使得我们不可能为所有的NLP任务规定一个单一的最佳性能解决方案。例如,适用于部分语音标记的词嵌入在情感分析上的表现可能不比随机嵌入好。从这样的评估中得出的结论应该仅限于特定的任务或类似的任务组,而不能推广到其他不同性质的任务中。
第二个限制则在于在外延评估框架中更难控制所有的因素。在一个典型的NLP系统中,有许多参数对最终的表现起着作用;有时即使是配置上的微小变化也会极大地改变结果。这使得从外在评价中得出普遍可靠的结论变得更加困难。一个在特定系统配置中表现良好的嵌入模型,例如在情感分析中,在其他情感分析系统中甚至同一模型的不同配置中未必表现良好。因此,人们应该非常谨慎地使用评估基准,更重要的是,应该谨慎地使用它们做出的结论。一个合理的做法是在不同的数据集和任务上混合使用内涵和外延评估。