强大的transformer
1. Introduction
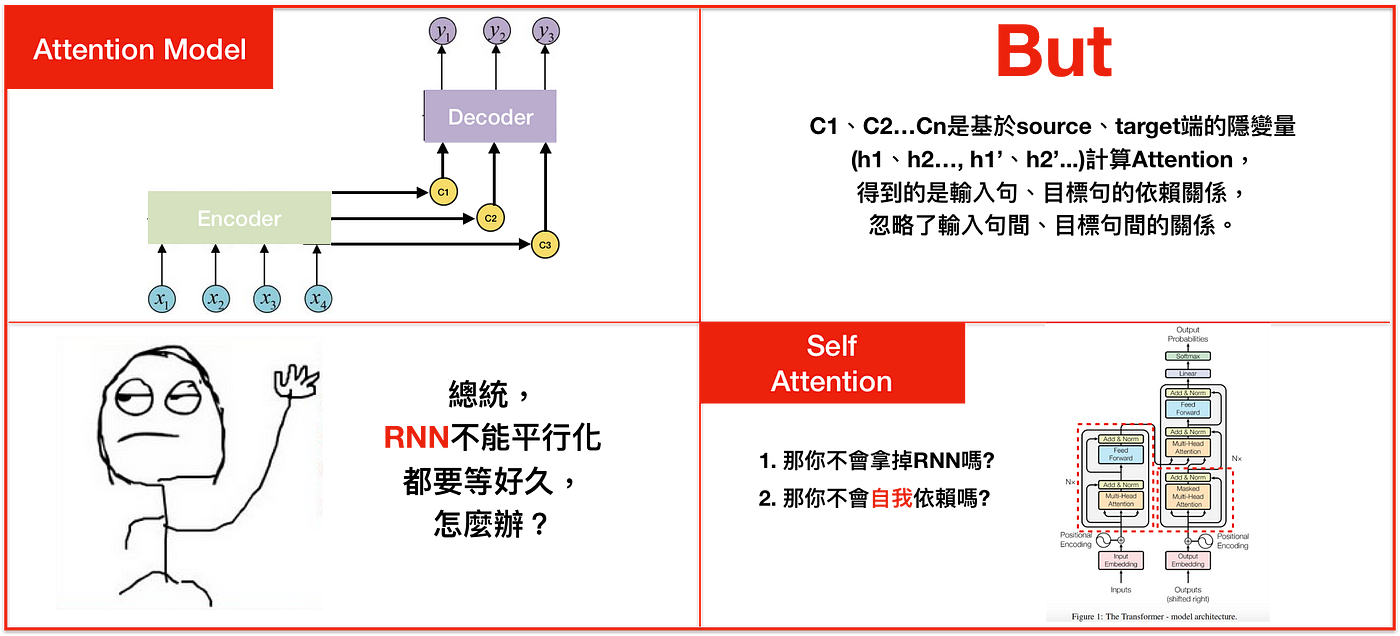
在transformer模型问世以前,序列建模任务最常用的模型就是sequence-to-sequence了,尤其是随着各种attention机制的加入,attention-based seq2seq模型获得了更好的性能从而得到了更广泛的应用。
不过RNN也有自己的问题:
-
无法并行,导致训练偏慢
-
句间依赖
序列问题其实包括了三种依赖:源句子内部依赖 ,目标句子内部依赖,源句子与目标句子之间的依赖。这三种依赖关系对于从源句子到目标句子的转换都十分重要,而seq2seq则无法建模这三种依赖,哪怕加上了attention,也只是捕捉到了源句子与目标句子间的依赖,另外两种依赖仍旧无法建模。
-
对长序列建模能力不足
由于RNN结构的串行特征,越往后面,它内部的信息对于最初的信息的记忆就会越少,导致在处理长序列的时候,句子开头的信息保留的就会非常少,从而对于句子的建模信息完整性缺失。
由于seq2seq的这些缺陷,促进了学者们针对新的架构提出了更多的关注,Facebook有人提出了一种基于CNN的seq2seq模型,这类模型拥有CNN的特性,可以很好的实现并行,不过其性能提升并不大。终于,在2017年,一篇新作《Attention Is All You Need》被提出,transformer横空出世,它有着CNN那样的并行效率,同时又有着高于seq2seq的性能,从而拉开了自己精彩的一生。
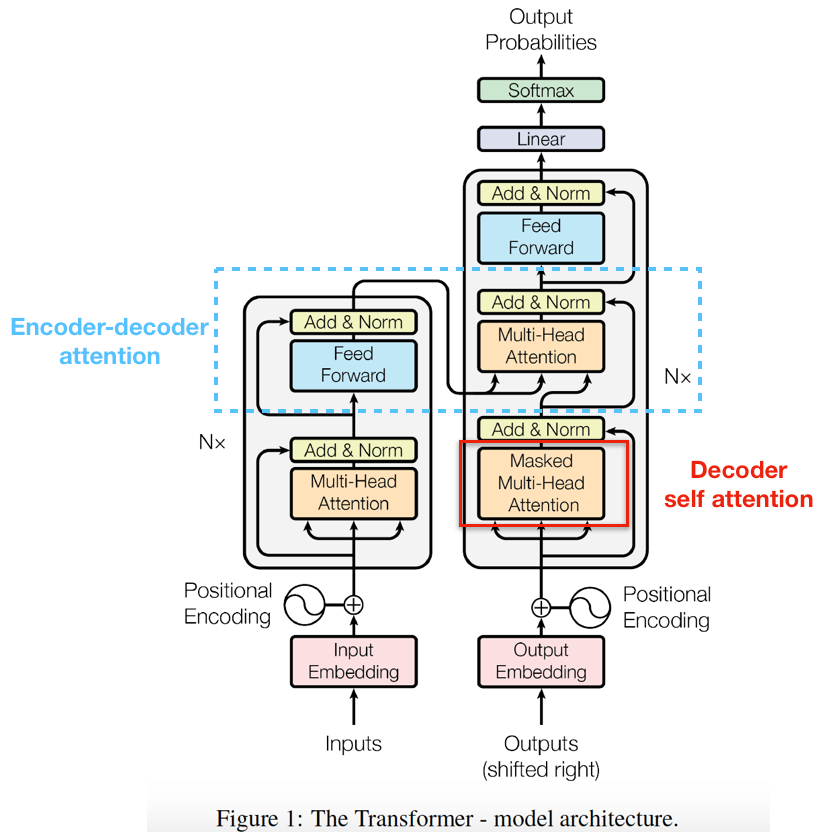
2. 架构总览
先看一下transformer的整体架构,有个总体印象:
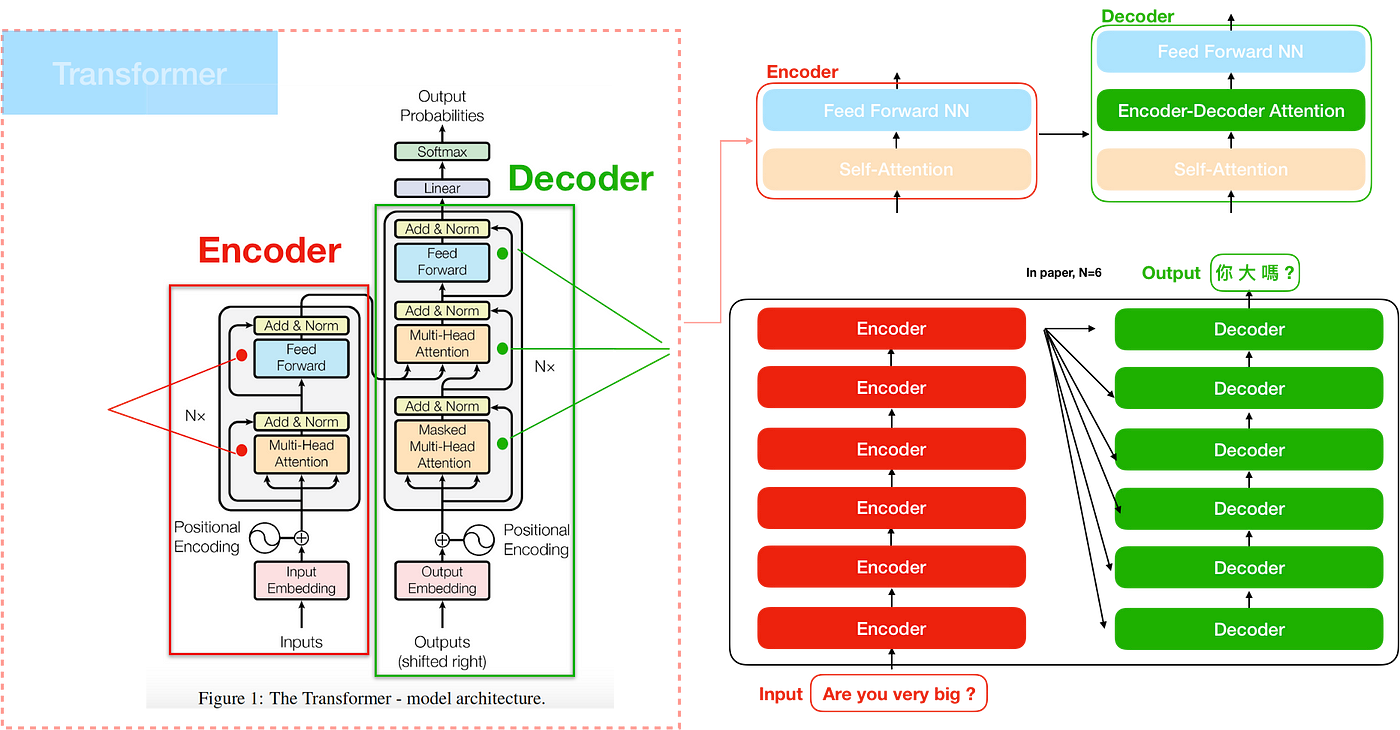
从模型上来看,transformer本身并不复杂,理解了它的几个组件,便可以理解其实现原理:
- Self-Attention
- Multi-Head Attention
- Positional Encoding
- Masked multi-head attention&Encoder-Decoder Attention
3. 组件
3.1 Self-Attention
transformer的attention不同于seq2seq中的attention,它使用的是一种称为self-attention的机制。在介绍self-attention以前,首先需要明确几个概念,即Query/Key/Value.
query/key/value的概念来自于信息检索领域,例如,当你在Youtube上输入一个query来搜索某个视频时,搜索引擎会将你的query与数据库中与候选视频相关联的一组key(视频标题、描述等)进行映射,然后向你展示最佳匹配的视频(value),所以key代表的是其实就是query的属性,value则是与query匹配的程度。一个简单粗暴的比喻是在档案柜中找文件。query向量就像一张便利贴,上面写着你正在研究的课题。key向量像是档案柜中文件夹上贴的标签。当你找到和便利贴上所写相匹配的文件夹时,拿出它,文件夹里的东西便是value向量。只不过我们最后找的并不是单一的value向量,而是很多文件夹value向量的混合。回到attention方面,attention本质上也是从一个集合中发现与本token最匹配的元素,所以也可以认为是一个检索过程。
从比较早的attention开始,attention score的计算方式为: \(c=\sum_{j}\alpha_{j}h_{j} \quad \sum \alpha_{j}=1\) 如果$\alpha$是个one-hot向量,那么这时候显然就是从$h$中检索出一条向量,如果$\alpha$是softmax向量,那么就是以概率向量$\alpha$进行比例检索。不过这类型的attention有个问题。
到了transformer中,由于是self-attention,所以attention的计算是在源句子或者目的句子上进行的,所以这里的query/key/value有一些变化,基本上来讲:
- Query:代表token的representation vector
- Key: 表征token属性的向量
- Value: memory,Query包含的信息,这里就类似于RNN中的hidden state
这三种vector可以通过矩阵乘法很容易进行实现。

这里的一般看法是输入句中的每个文字是由一系列成对的<地址Key, 元素Value>所构成,而目标中的每个文字是Query,那么就可以用Key, Value, Query去重新解释如何计算context vector ,透过计算Query和各个Key的相似性,得到每个Key对应Value的权重系数,权重系数代表讯息的重要性,亦即attention score;Value则是对应的讯息,再对Value进行加权求和,得到最终的Attention/context vector。
不过,个人感觉应该借鉴了Facebook提出的memory network思想,Query,Key,Value分别对应I(input feature map),G(generalization),O(output feature map)模块,通过将输入x变换到Query实现I的操作,然后用Query与Key计算匹配程度,实现G操作,最终通过权重向量与Value实现O操作。
self-attention接收n个输入,同时产生n个输出。它内部通过在输入之间进行交互(self),来让每个输入找到它最应该关注的另外一个输入(attention)。self-attention的运算其实非常简单,

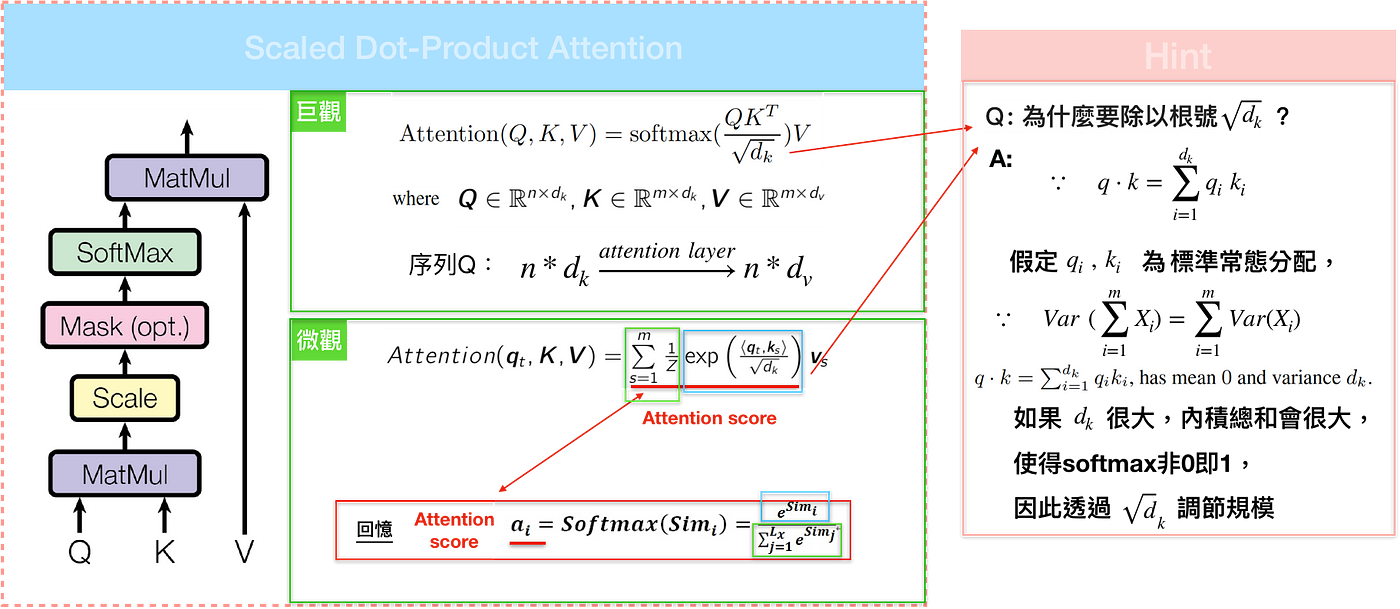
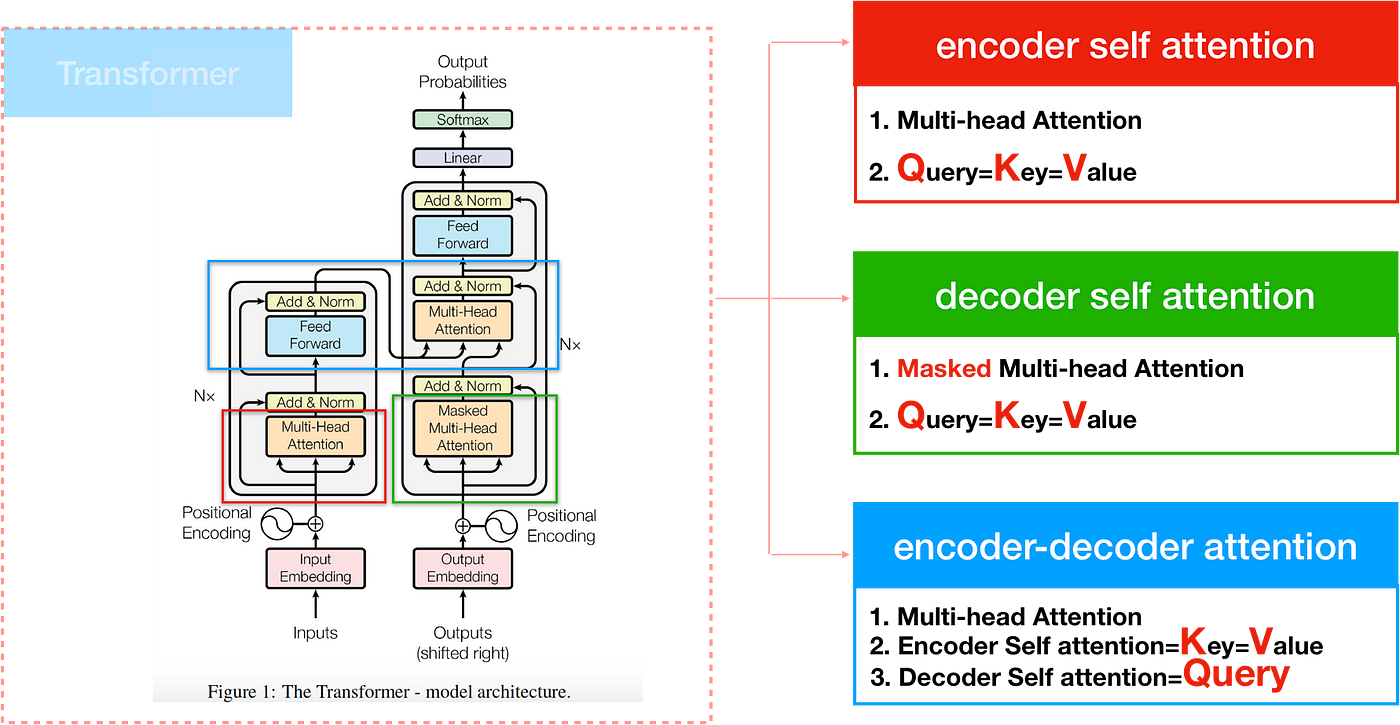
这里还有个要注意的地方,那就是从总览图可以看出,decoder与encoder的attention是存在一些区别的。
3.2 Multi-Head Attention
Multi-head Attention其实就是多个Self-Attention结构的结合,每个head学习到在不同表示空间中的特征。

那么,为何要使用这个Multi-head呢?单个self-encoder不够么?
答案是,还真的不够。只计算一个attention,很难捕捉到句子中的所有信息。通过multi-head的使用,一般认为可以带来两个方面的好处:
- 它扩展了模型专注于不同位置的能力。在上面的例子中,虽然每个编码都在z1中有或多或少的体现,但是它可能被实际的单词本身所支配。如果我们翻译一个句子,比如“The animal didn’t cross the street because it was too tired”,我们会想知道“it”指的是哪个词,这时模型的“多头”注意机制会起到作用。
- 它给出了注意力层的多个“表示子空间”(representation subspaces),不同的空间可以代表不同方面的信息。

不过,关于multi-head是否有效,以及为何有用,还没有一个很好的解释。
有大量的研究表明,以Transformer为基础的Bert的特定层是有其独特的功能的,底层更偏向于关注语法,顶层更偏向于关注语义。既然在同一层Transformer关注的方面是相同的,那么对该层而言,不同的头关注点应该也是一样的。这和上面的好处存在矛盾之处。
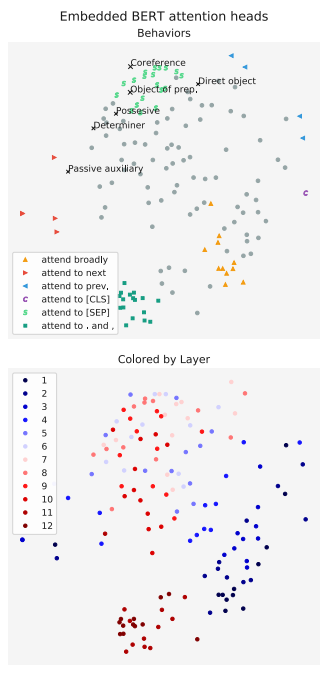
实际上,在《A Multiscale Visualization of Attention in the Transformer Model》这篇文章中,作者分析了前几层BERT的部分注意力头,如下图所示,结果显示,同一层中,总有那么一两个头关注的点和其他的头不太一样,但是剩下的头也相对趋同【考虑到同一层的注意力头都是独立训练的,这点就很神奇】。
横轴为Heads,纵轴为layers.Bert的不同层及相同层的不同head对于同样的输入所关注的内容 在《What Does BERT Look At? An Analysis of BERT’s Attention》一文中,作者分析了,同一层中,不同的头之间的差距,以及这个差距是否会随层数变化而变化。结果如下图所示,似乎可以粗略地得出结论,头之间的差距随着所在层数变大而减少,即层数越高,头越趋同。但遗憾的是,这个现象的原因目前没有比较好的解释。
对于Bert中,每一层的head之间的差异在二维平面上的投影 按照上面的研究,大致可以看出每一层的multi-head中attention是存在很多冗余的,即使是独立计算的注意力头,大概率关注的点还是一致的。如果全部的head都关注于同样的内容,那么很显然对于下层语义的提取是不充分的,而那些特立独行的head因为关注到了额外的信息,所以能使模型的能力得到进一步的优化。而为了增加那些特立独行的head的出现概率,所以需要使用multi。

# MultiHeadedAttention实现
class MultiHeadedAttention(nn.Module):
def __init__(self, h, d_model, dropout=0.1):
"Take in model size and number of heads."
super(MultiHeadedAttention, self).__init__()
assert d_model % h == 0
# We assume d_v always equals d_k
self.d_k = d_model // h
self.h = h
self.linears = nn.ModuleList([nn.Linear(d_model, d_model) for _ in range(4)])
self.attn = None
self.dropout = nn.Dropout(p=dropout)
def forward(self, query, key, value, mask=None):
'''
Implements multihead.
:param query: (batch_size, seq_len, embeding_size)
:param key: (batch_size, seq_len, embeding_size)
:param value: (batch_size, seq_len, embeding_size)
:param mask: 若不为None,shape:(batch_size,1, 1 or seq_len, seq_len)
:return: z (batch_size, seq_len, embedding_size)
'''
nbatches = query.size(0)
# 1) Do all the linear projections in batch from d_model => h x d_k
query, key, value = \
[l(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2)
for l, x in zip(self.linears, (query, key, value))]
# 2) Compute 'Scaled Dot Product Attention'.
d_k = query.size(-1)
scores = torch.matmul(query, key.transpose(-2, -1)) \
/ math.sqrt(d_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
p_attn = F.softmax(scores, dim = -1)
if self.dropout is not None:
p_attn = self.dropout(p_attn)
x = torch.matmul(p_attn, value)
# 3) "Concat" using a view and apply a final linear.
x = x.transpose(1, 2).contiguous() \
.view(nbatches, -1, self.h * self.d_k)
return self.linears[-1](x)
3.3 Positional Encoding
进行到这里的时候,你可能会发现一个问题,attention的运算只涉及到了token的vectors的运算,而没有任何的位置信息,而缺失了这个信息,其实相当于丢失了序列信息,这对于文本这种存在着明显时序信息的序列来说很显然是不行的。这个该怎么解决呢?答案就是Positional Encoding。
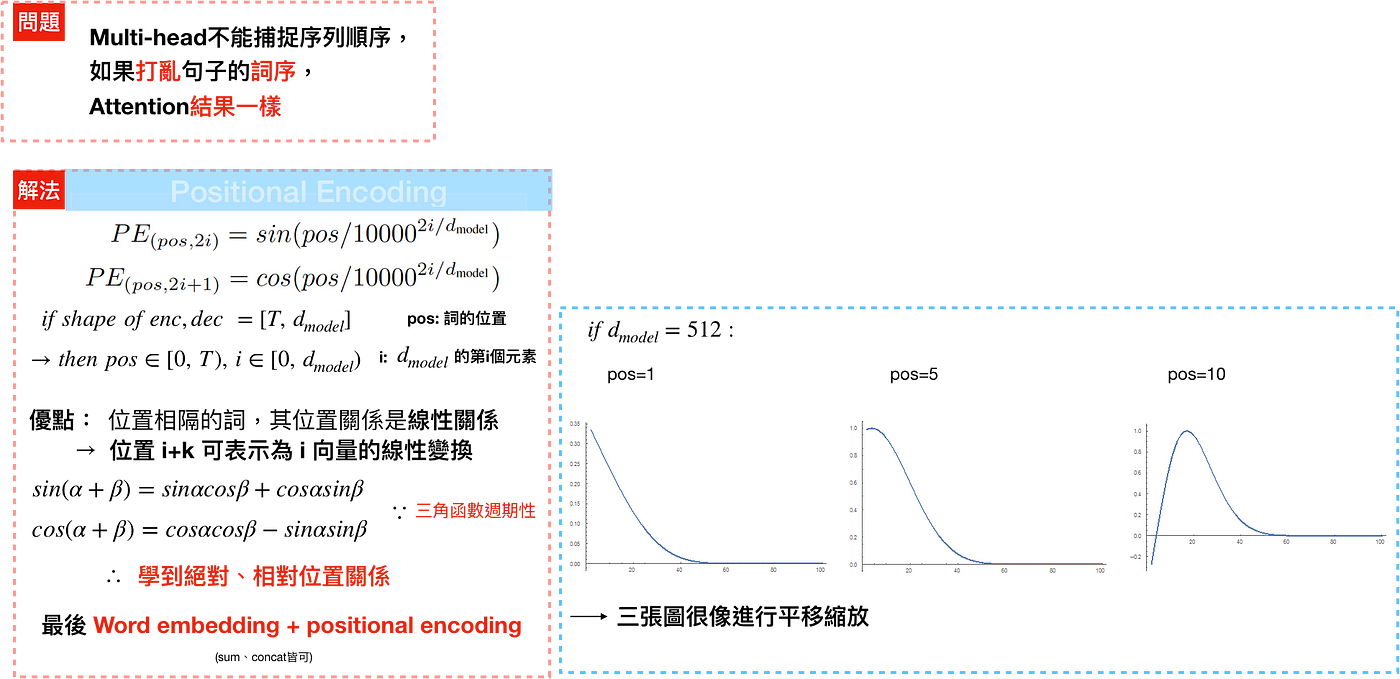
这种处理方式能够扩展到未知的序列长度(例如,当我们训练出的模型需要翻译远比训练集里的句子更长的句子时)。
注意下方实现中的exp运算: \(1/10000^{2i/d_{model}}=e^{log10000^{−2i/d_{model}}}=e^{−2i/d_{model}*log10000}=e^{2i*(−log10000/d_{model})}\)
class PositionalEncoding(nn.Module):
"Implement the PE function."
def __init__(self, d_model, dropout, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
# Compute the positional encodings once in log space.
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2) *
-(math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
x = x + Variable(self.pe[:, :x.size(1)],
requires_grad=False)
return self.dropout(x)
3.4 Masked multi-head attention&Encoder-Decoder Attention
Masked multi-head attention是个用于decoder模块小的点,目的是为了防止在decode的时候提前看到后面的词,具体做法是在计算self-attention的softmax前先mask掉未来的位置(设为-∞),这样就可以在预测位置i的时候只能根据i之前位置的输出。
Encoder-Decoder Attention则是encoder和decoder进行交互的attention,它的Query來自於decoder self-attention,而Key、Value則是encoder的output。
# 构建mask
def make_src_mask(src, pad):
'''
:param src: (batch_size, seq_len)
:param pad: pad id
:return: mask (batch_size, 1, 1, seq_len)
'''
return (src!=pad).unsequeeze(1).unsqueeze(1)
def make_tgt_mask(tgt, pad):
'''
Create a mask to hide padding and future words.
:param tgt: (batch_size, seq_len)
:param pad: pad id
:return: mask (batch_size, 1, seq_len, seq_len)
'''
tgt_mask = (tgt != pad).unsqueeze(-2)
attn_shape = (1, tgt.size(-1), tgt.size(-1))
subsequent_mask = np.triu(np.ones(attn_shape), k=1).astype('uint8')
subsequent_mask = torch.from_numpy(subsequent_mask) == 0
tgt_mask = tgt_mask & subsequent_mask.type_as(tgt_mask.data)
return tgt_mask.unsqueeze(1)
4.一些总结
到这里为止transformer的一些重要的点就介绍完了,回过头来看看transformer,做个总结:
-
Transformer为何使用多头注意力机制,而不是不使用一个头?
这个问题虽然作者声称是多头保证了transformer可以注意到不同子空间的信息,捕捉到更加丰富的特征信息。不过就像上面附注部分写的一样,这个解释是不那么合理的,现在也有了很多研究是关于多头为何有效的,不过也都没有很好的解释出原因。所以,姑且认为这是作为探索的结果吧。。。另外,从下图作者的结果来看,头也不是越多越好的。

-
Transformer为什么Q和K使用不同的权重矩阵生成,为何不能使用同一个值进行自身的点乘?
使用两个权重矩阵和使用一个矩阵的区别是什么? 很简单,就是多了个矩阵而已。而在深度学习领域,多个了矩阵其实就是多了个参数,我们很自然的想到就是多了个参数,所以表达能力更强了,结果就是泛化能力更强了。
另外就是,想象一下如果只使用一个矩阵的后果,假设qk代表的相似性,那么对于两个token A和B,$q_{a}k_{b},q_{b}k_{a}$分别代表A对B的相关性和B对A的相关性,只用一个矩阵的情况下这两个值是相同的,也就是他们的相关性是相同的,这个究竟合理不合理呢?
-
Transformer计算attention的时候为何选择点乘而不是加法?两者计算复杂度和效果上有什么区别?
为了更快罢了,矩阵乘法有着专门的优化算法。不过如果不进行scale的话加法效果好于点乘,因为点乘后qk的分布方差变大,进行softmax以后概率值会更偏向个较大的值,从而导致梯度消失现象,所以作者通过scale $\frac {1}{d_k}$来缓解。
4.总结
transformer模型的提出从根本上改革了以RNN为基础的一系列序列建模任务,它在很多方面都超脱于RNN结构网络,并为后续的横扫Nlp各大任务的Bert模型奠定了基础。
不过,transformer作为先行者,其结构也必然存在着不足之处:
-
非图灵完备性,导致其泛化性并不是特别宽泛,导致其不能处理所有的任务
因为在Transformer中,单层中sequential operation (context two symbols需要的操作数)是O(1) time,独立于输入序列的长度。那么总的sequenctial operation仅由层数T决定。这意味着transformer不能在计算上通用,即无法处理某些输入。如:输入是一个需要对每个输入元素进行顺序处理的函数,在这种情况下,对于任意给定的深度TT的transformer,都可以构造一个长度为N > TN>T的输入序列,该序列不能被transformer正确处理。
-
不适合处理超长序列
当针对文章处理时,序列的长度很容易就超过512。而如果选择不断增大模型的维度,训练时计算资源的需求会平方级增大,难以承受。因此一般选择将文本直接进行截断,而不考虑其自然文本的分割(例如标点符号等),使得文本的长距离依赖建模质量下降。
-
transformer缺少conditional computation,计算资源分配对于不同的单词都是相同的
在Encoder的过程中,所有的输入token都具有相同的计算量。但是在句子中,有些单词相对会更重要一些,而有些单词并没有太多意义。为这些单词都赋予相同的计算资源显然是一种浪费。
虽然如此,transformer仍旧是一种非常有效的特征抽取器,后续也有非常多的研究致力于解决其缺陷,我们后续会介绍其他的一些针对transformer的改进。