nlp领域的巧妙trick
1. adaptive softmax
ICML 2017文章,该方法的灵感来自于hierarchy softmax及其变体,通过一种近似策略来实现超大词典上的语言模型的有效训练。
1.1 特点
- 该算法的提出利用到了单词分布不均衡的特点(unbalanced word distribution)来形成将单词分成不同的类, 这样在计算softmax时可以避免对词汇量大小的线性依赖关系,降低时间复杂度;
- 通过结合现代架构和矩阵乘积操作的特点,使其更适合GPU单元的方式进一步加速计算。
1.2 提出动机
 \(general\,softmax = HW \quad H \in R^{(B*d)},W \in R^{d*k}\\(B:batch\,size, d: hidden\,dimension, k:size\,of\,vocabulary)\)
\(general\,softmax = HW \quad H \in R^{(B*d)},W \in R^{d*k}\\(B:batch\,size, d: hidden\,dimension, k:size\,of\,vocabulary)\)
-
$W$很大的时候,十分耗时,如果固定d和$B$,上图的曲线记为函数$g(k)$,可以看到,大概在$k<k_{0} \approx 50$时,时间$g(k)$是一个常量。直到$k>k_{0}$时, 时间$g(k)$变成成了一个线性函数, 固定d和$K$的时候,也有类似规律,表明矩阵相乘时,当其中一个维度很小时,矩阵乘法是低效的。也就是说计算大量小矩阵是不划算的,很容易理解,数据传输、函数调用开销等也需要消耗时间。也说明了,按层次来组织words时,如果中间节点有较少的子节点时 (比如huffman 编码的tree)是次优的。
-
在自然语言中,单词的分布遵循Zipf定律。大部分的概率被词典中一小部分词所覆盖,例如,在Penn TreeBank中87%的文档只被20%的词汇所覆盖。
-
词分类,通过词的词频将其划分到不同的类目中去
-
每个类(cluster)是独立的被访问,因此它们不需要有相同的能力。对应频繁的词它们使用跟高的能力,而稀少的词他们可以不被学的非常好,因为它们很少被查看。
-
对不同的类共享隐层,通过加映射矩阵的方式降低分类器的输入大小。一般的,tail部分(低频词部分)的映射矩阵将其大小从$d$维缩小到$d_{t}=d/k^{i},(i为簇的编号,k默认为4)$维,比如head为d,k=4,则tail 1的维度为$d/4$,tail 2的维度为$d/4^{2}$,等等
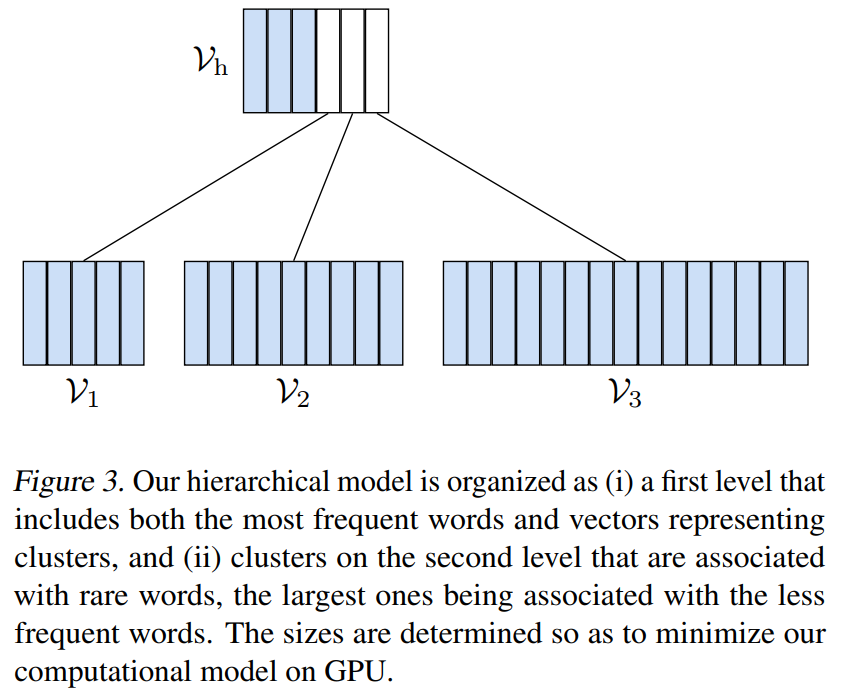
1.3 工程实践
层次softmax,每个tail$(V_{tail})$在head中占据一个字符位置,比如Figure 3中,三个tail部分在head中占据了3个位置。对于head部分,预测概率即为一次softmax的概率;对于tail部分,预测概率为在head中选择该tail的概率加上该tail内部进行softmax后的概率。pytorch中已经有相关的实现,直接调用即可。
2. region embedding
ICLR 2018论文,是一种用于文本分类的embeddings技术。在文本分类中,通常使用词袋模型作为文档的represention来进行分类,然而,词袋模型有它的限制。他对单词的表示没有包含单词的顺序信息。N-gram解决了这一问题,但n-gram也有局限: 当n较大时,通常有数据稀疏性问题。直观上来讲,一个字的含义通常应该由它自身的含义以及它所处的上下文的字的含义来共同决定,所以在本论文中,作者提出了一个字的extend embeddings也应该包含两部分:self-embedding和一个用来和局部上下文交互的矩阵(local context unit)组成,这就是region embedding概念。region embedding有两部分组成:单词本身的embedding向量表示,上下文的embeddings以及与上下文关联的矩阵表示。文本看作是region embedding的集合。在进行文本分类的时候,针对文本构建n-gram的extend embedding,构造方式为使用n-gram中的所有词的extend embedding来构建,然后拿去分类。论文中共提出了两种模型,Word-Context Region Embedding和Context-Word Region Embedding.

2.1 local context unit
region本身代表单词所处的一个短序列,Region(i,c)表示下标为i的词为中心词和左右两边各长度为c的上下文组成的序列。例如,句子The food is not very good in this hotel, region(3, 2)指的就是food is not very good。
定义单词$w_{i}$的local context unit为$K_{w_{i}} \in R^{h(2c+1)}$,$h$为embedding size,这里可以使用一个shape为$(h(2c+1),v)$的embedding层进行实现,$v$为vocabulary size。那么,context unit的每一个向量(长度为$h$)可以构建$w_{i}$到其context words的project,得到projected word embedding, 这个projected word embedding因为通过模型进行学习,因而可以捕获到$w_{i}$与context word的语义和句法信息。
设$P_{w_{i+t}}^{i}$是$w_{i}$在其相对位置$t(-c<=t<=c)$的word的projected word embedding,$K_{w_{i},t}$为$K_{w_{i}}$的第$t$项,计算方式为: \(P_{w_{i+t}}^{i}=K_{w_{i},t}\odot e_{w_{i+t}}\)
2.1 Word-Context Region Embedding
该模型专注于中心词对context words的影响。因而使用中心词的local context unit,context words则使用其embedding,获得projected embeddings以后进行max pool 来获得最有预测性的特征,从而得到region embedding$r_{i,c}$: \(r_{i,c}=max([P_{w_{i-c}}^{i},P_{w_{i-c+1}}^{i}...P_{w_{i+c-1}}^{i},P_{w_{i+c}}^{i}])\) max在batch维上进行,最后得到的region embedding长度也是$h$.
2.2 Context-Word Region Embedding
这种结构则是专注于context words对于中心词的影响,因而使用context words的local context unit,中心词则使用其embedding: \(r_{(i,c)}=max([P_{w_{i}}^{i-c},P_{w_{i}}^{i-c+1}...P_{w_{i}}^{i+c-1},P_{w_{i}}^{i+c}])\)
3.adaptive input embeddings
ICLR 2019论文,adaptive softmax的拓展,其思路比较简单,一张图即可表达:

其背后理论是,词的频率是很不同的,更新Embedding层时,低频的词应该用更少的资源,可以防止过拟合;高频的词可以增加一些资源(这里的资源尤指维度),而且高频的词的一词多义的现象更加明显,增加资源可以增强embedding的表达能力。所以根据词频划分不同的簇,思路和adaptive softmax一致,不同点在于adaptive softmax是针对分类层的,而该方法是针对embedding层的,相当于模型的两个源头,adaptive softmax作用于下游,而该方法作用于上游。