Bert家族
1. introduction
Bert,目前nlp领域神器级模型,诞生于2018年,全称Bidirectional Encoder Representation from Transformers。该模型在其诞生时,在机器阅读理解顶级水平测试SQuAD1.1中表现出惊人的成绩:全部两个衡量指标上全面超越人类,并且还在11种不同NLP测试中创出最佳成绩,包括将GLUE基准推至80.4%(绝对改进7.6%),MultiNLI准确度达到86.7% (绝对改进率5.6%)等,引起了极大的轰动。经过2年的发展,在标准的Bert模型基础上又诞生了相当多的改进,十分有必要学习一下目前的进展。
2. 模型发展综述
2.1 Bert
Bert模型的开端,它在工程上没有什么特别大的创新,如果懂了transformer,那么基本上就懂了模型的大概,重要的理解其背后的思想。Bert的paper名字叫做:Pre-training of Deep Bidirectional Transformers for Language Understanding,papar name基本包含了所有的内容。
2.1.1 Deep Bidirectional Transformers
pre-training技术并不新鲜,在Bert之前的很多模型,比如ELMo和GPT上已经得到了应用,不过这些模型多少还存在不足。
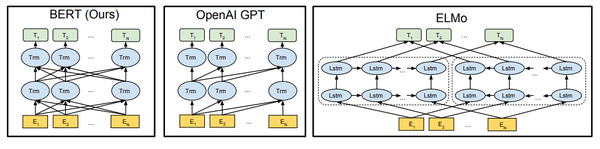
对比OpenAI GPT(Generative pre-trained transformer),Bert是双向的Transformer block连接;就像单向RNN和双向RNN的区别,这种结果能让模型获得更丰富的信息,从而获得更强的表达能力。
对比ELMo,虽然都是“双向”,但目标函数其实是不同的。ELMo是分别以 和
作为目标函数,独立训练处两个representation然后拼接,而Bert则是以
作为目标函数训练LM,所以Bert在信息融合层面显然要比ELMo更强大,效果也更好。
2.1.2 Pre-training
这里应该就是Bert比较有创新的地方了,论文中,作者使用了两种预训练策略:
- Masked Language Modeling
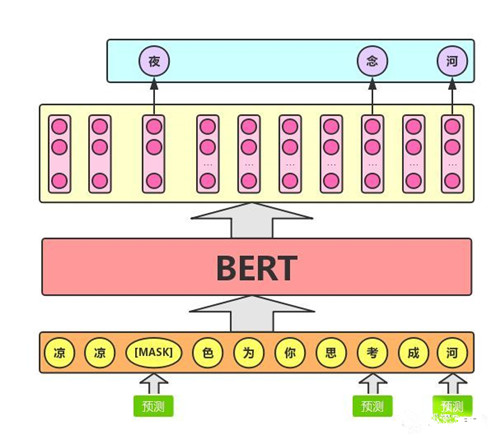
假设有这样一个句子:“我喜欢阅读Analytics Vidhya上的数据科学博客”。想要训练一个双向的语言模型,可以建立一个模型来预测序列中的遗漏单词,而不是试图预测序列中的下一个单词。将“Analytics”替换为“[MASK]”,表示丢失的标记。然后,以这样的方式训练模型,使其能够预测“Analytics”是本句中遗漏的部分:“我喜欢阅读[MASK]Vidhya上的数据科学博客。”。这样处理后,预测一个词汇时,模型并不知道输入对应位置的词汇是否为正确的词汇(10%概率),这就迫使模型更多地依赖于上下文信息去预测词汇,并且赋予了模型一定的纠错能力。
这是Masked Language Model的关键。BERT的开发者还提出了一些进一步改进该技术的注意事项:
1)为了防止模型过于关注特定的位置或掩盖的标记,研究人员随机掩盖了15%的词(个人认为这里设为15%有加速收敛的效果,毕竟mask比例越大则信息损失越多,模型从未mask的token中恢复信息需要的训练轮次也越多),这样的处理使得模型只会预测语料库中的15%单词,而不会预测所有的单词。
2)掩盖的词并不总是被[MASK]替换,因为在微调时不会出现[MASK]。
研究人员使用了以下方法:
o [MASK]替换的概率为80%
o 随机词替换的概率为10%
o 不进行替换的概率为10%
这种策略就是普通语言模型。
- Next Sentence Prediction
Masked Language Model是为了理解词之间的关系。BERT还接受了Next Sentence Prediction训练,来理解句子之间的关系。
问答系统 question answering systems是一个不错的例子。该任务十分简单。给定两个句子,句A和句B,B是语料库中在A后面的下一个句子,还是只是一个随机的句子?
由于它属于到二分类任务,通过将数据拆分为句子对,就可以很容易地从任何语料库中生成数据。就像Masked Language Model一样,研发者也在这里添加了一些注意事项。例如:
假设有一个包含100,000个句子的文本数据集。因此,将有5万个训练样本或句子对作为训练数据。
• 其中50%的句子对的第二句就是第一句的下一句。
• 剩余50%的句子对,第二句从语料库中随机抽取。
• 第一种情况的标签为‘IsNext’ ;第二种情况的标签为‘NotNext’。

这就是BERT为什么能够成为一个真正的任务无关模型。因为它结合了Masked Language Model (MLM)和Next Sentence Prediction (NSP)的预训练任务。
2.1.3 超强的通用性
如果Bert只是性能好而通用性欠佳,那么大概也不会导致这么大的反响,不过Bert在性能强的同时又保证了良好的通用性,这就没有不火的理由了。Bert通过良好的预处理方式,保证了自己的良好通用性。
1)文本分类任务
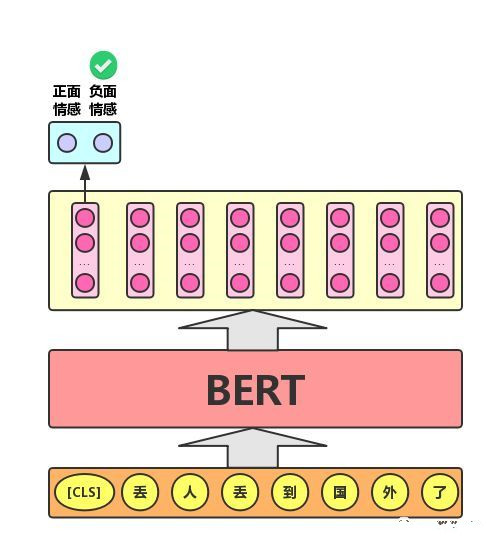
单文本分类任务:对于文本分类任务,Bert模型在文本前插入一个[CLS]符号,并将该符号对应的输出向量作为整篇文本的语义表示,用于文本分类,如下图所示。可以理解为:与文本中已有的其它字/词相比,这个无明显语义信息的符号会更“公平”地融合文本中各个字/词的语义信息。
2)语句对分类任务
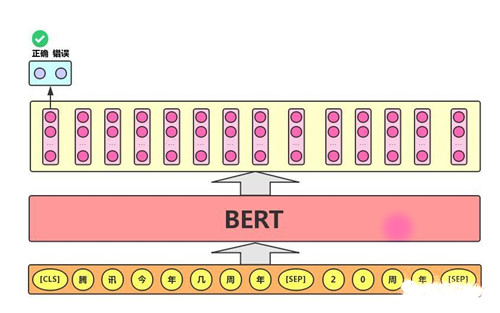
语句对分类任务:该任务的实际应用场景包括:问答(判断一个问题与一个答案是否匹配)、语句匹配(两句话是否表达同一个意思)等。对于该任务,BERT模型除了添加[CLS]符号并将对应的输出作为文本的语义表示,还对输入的两句话用一个[SEP]符号作分割,并分别对两句话附加两个不同的文本向量以作区分,如下图所示:
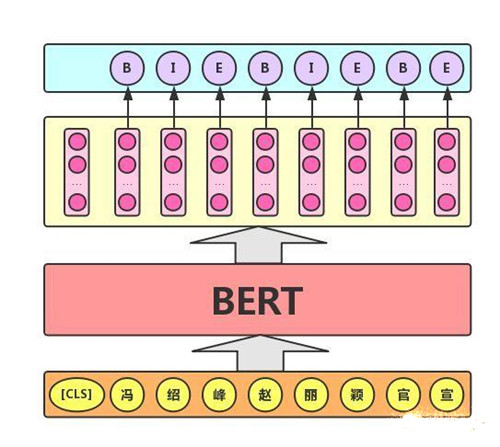
3)序列标注任务
该任务的实际应用场景包括:中文分词&新词发现(标注每个字是词的首字、中间字或末字)、答案抽取(答案的起止位置)等。对于该任务,BERT模型利用文本中每个字对应的输出向量对该字进行标注,如下图所示(B、I、E分别表示一个词的第一个字、中间字和最后一个字)。
Bert模型整体输入/输出:
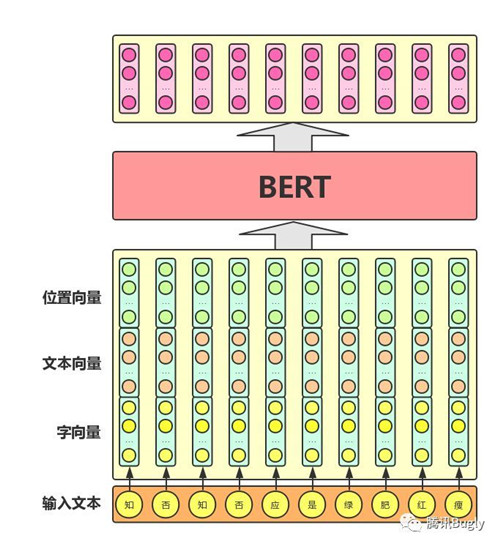
从图可以看出,其混合了三种向量:
- 字向量:普通的Embedding输出。
- 文本向量:该向量的取值在模型训练过程中自动学习,用于刻画文本的全局语义信息,并与单字/词的语义信息相融合,适用于语句对分类任务,表示word属于哪个句子。
- 位置向量:同标准的transformer。
2.2 XlNet
Bert的引入为nlp打开了一道新的大门,不过不代表其就是完善的,分别看一下Bert的两个重要机制:
- Masked
Bert在做pre-train的时候,是预测被那些被[MASK]替换的token,而在fine-tuning的时候,输入文本中是没有[MASK]的,这很显然就会导致一个bias的问题,尽管作者也意识到了这个问题,并设计了一些替换策略,比如用替换为其他正常词而非[MASK],不过在pre-train的时候只有15%的词会被替换,然后替换的词中只有10%的词会被替换为其他正常词,这个比例这是一下只有1.5%,是非常低的。
- Parallel
这是Bert相比于RNN的一个优势,但是有得必有失,并行的加入是以失去部分序列依赖性为代价的,而对于RNN系列模型,由于每次都是从左向右或者从右向左,所以可以明显捕捉到依赖性。
Bert取得的重大进步就是通过捕捉双向语境来获得的,代价就是上面两个,那么问题就变成了,如果在保持Bert优势的基础上,克服上面的两个问题呢?XlNet给出了自己的答案。
在介绍XlNet以前,有必要了解两个概念:自回归语言模型(Autoregressive LM)和自编码语言模型(Autoencoder LM):
- 自回归语言模型(Autoregressive LM)
自回归模型(英语:Autoregressive model,简称AR模型),是统计上一种处理时间序列的方法,用同一变数例如

自回归语言模型有优点有缺点,缺点是只能利用上文或者下文的信息,不能同时利用上文和下文的信息,当然,貌似ELMO这种双向都做,然后拼接看上去能够解决这个问题,因为融合模式过于简单,所以效果其实并不是太好。它的优点,其实跟下游NLP任务有关,比如生成类NLP任务,比如文本摘要,机器翻译等,在实际生成内容的时候,就是从左向右的,自回归语言模型天然匹配这个过程。而Bert这种DAE模式,在生成类NLP任务中,就面临训练过程和应用过程不一致的问题,导致生成类的NLP任务到目前为止都做不太好。
- 自编码语言模型(Autoencoder LM)
自回归语言模型只能根据上文预测下一个单词,或者反过来,只能根据下文预测前面一个单词。相比而言,Bert通过在输入中随机Mask掉一部分单词,然后预训练过程的主要任务之一是根据上下文单词来预测这些被Mask掉的单词,如果你对Denoising Autoencoder比较熟悉的话,会看出,这确实是典型的DAE的思路。那些被Mask掉的单词就是在输入侧加入的所谓噪音。类似Bert这种预训练模式,被称为DAE LM。
这种DAE LM的优缺点正好和自回归LM反过来,它能比较自然地融入双向语言模型,同时看到被预测单词的上文和下文,这是好处。缺点嘛,就是上面提到的两个。
XLNet的出发点就是:能否融合自回归LM和DAE LM两者的优点。就是说如果站在自回归LM的角度,如何引入和双向语言模型等价的效果;如果站在DAE LM的角度看,它本身是融入双向语言模型的,如何抛掉表面的那个[Mask]标记,让预训练和Fine-tuning保持一致。问题有了,接下来就是解决了。
XLNet仍然遵循两阶段的过程,第一个阶段是语言模型预训练阶段;第二阶段是任务数据Fine-tuning阶段。它主要希望改动第一个阶段,就是说不像Bert那种带Mask符号的Denoising-autoencoder的模式,而是采用自回归LM的模式。就是说,看上去输入句子X仍然是自左向右的输入,看到$w_{t}$单词的上文Context_before,来预测$w_{t}$这个单词。但是又希望在Context_before里,不仅仅看到上文单词,也能看到$w_{t}$单词后面的下文Context_after里的下文单词,这样的话,Bert里面预训练阶段引入的Mask符号就不需要了,于是在预训练阶段,看上去是个标准的从左向右过程,Fine-tuning当然也是这个过程,于是两个环节就统一起来。那么,应该如何修改呢?说起来也很简单,那就是我随机重排输入的单词序列不就行了么,这样后面的单词有概率被分到前面去,这不就相当于看到上下文了么?XLNet正是这么做的,在论文中被称为Permutation Language Model。

以上图为例,输入序列为$x_{1},x_{2},x_{3},x_{4}$,假设要预测$x_{3}$,随机permutation一下得到序列$x_{3},x_{2},x_{4},x_{1}$,即左上角,因为$x_{3}$被排在了第一位,所以它的context-before 不存在单词,所以计算$x_{3}$的时候其他token不参与计算,再随机permutation一下得到右上角序列,$x_{3}$的context-before包括了$x_{2},x_{4}$,则计算的时候要考虑$x_{2},x_{4}$,下面两列同理。
思路是这么个思路,具体怎么实现呢?首先,需要强调一点,尽管上面讲的是把输入序列的单词排列组合后,再随机抽取例子作为输入,但是,实际上你是不能这么做的,因为Fine-tuning阶段你不可能也去排列组合原始输入。所以,就必须让预训练阶段的输入部分,看上去仍然是x1,x2,x3,x4这个输入顺序,但是可以在Transformer部分做些工作,来达成我们希望的目标。具体而言,XLNet采取了Attention掩码的机制,可以理解为,当前的输入句子是X,要预测的单词$w_{t}$是第t个单词,前面1到t-1个单词,在输入部分观察,并没发生变化,该是谁还是谁。但是在Transformer内部,通过Attention掩码,从X的输入单词里面,也就是的上文和下文单词中,随机选择i-1个,放到$w_{t}$的上文位置中,把其它单词的输入通过Attention掩码隐藏掉,于是就能够达成我们期望的目标,当然这个所谓放到$w_{t}$的上文位置,只是一种形象的说法,其实在内部,就是通过Attention Mask,把其它没有被选到的单词Mask掉,不让它们在预测单词Ti的时候发生作用,如此而已。看着就类似于把这些被选中的单词放到了上文Context_before的位置了。XLNet是用“双流自注意力模型”来实现这个目标。
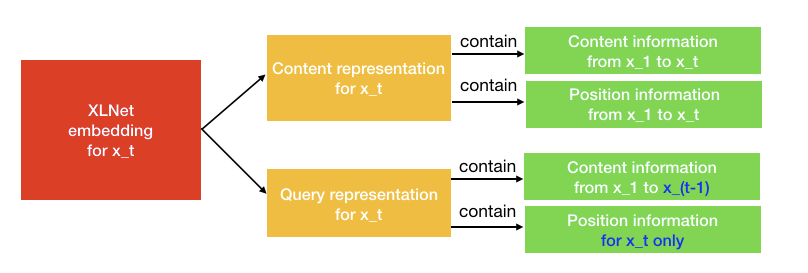
$XLNet$与$Bert$不同之处在于,一个token $x3$将服务两种角色。当它被用作内容来预测其他标记时,我们可以使用内容表示(通过内容流注意力来学习)来表示$x3$。但是如果我们想要预测$x3$,我们应该只知道它的位置而不是它的内容。这就是为什么$XLNet$使用查询表示(通过查询流注意力来学习)来保留$x3$之前的上下文信息,只保存$x3$的位置信息。
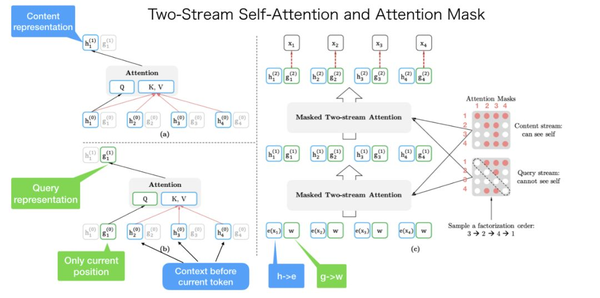
以上图为例,这个句子的原始顺序是$[x1, x2, x3, x4]$。我们随机得到一个分解的顺序为$[x3, x2, x4, x1]$。
左上角是内容表示的计算。如果我们想要预测$x1$的内容表示,我们应该拥有所有4个token内容信息。$KV = [h1, h2, h3, h4]$和$Q = h1$。
左下角是查询表示的计算。如果我们想要预测$x1$的查询表示,我们不能看到$x1$本身的内容表示。$KV = [h2, h3, h4],Q = g1$。
右下角是整个计算过程。我把它从头到尾解释了一遍。首先,$h$和$g$被初始化为$e(xi)[word \ Embeding]$和$w[可学习参数]$。在内容掩码和查询掩码之后,双流注意力将输出第一层输出$h^(1)$和$g^(1)$,然后计算第二层。
注意右边的内容掩码和查询掩码。它们都是矩阵。在内容mask中,第一行有4个红点。这意味着第一个$token (x1)$可以看到(注意到)所有其他tokens,包括它自己$(x3->x2->x4->x1)$。第二行有两个红点。这意味着第二个$token (x2)$可以看到(注意到)两个$token(x3->x2)$。等等。
内容掩码和查询掩码之间惟一的区别是,查询掩码中的对角元素为0,这意味着token不能看到它们自己。
与传统语言建模相比,Permutation Language Model更具挑战性,这显然会导致模型收敛缓慢。为了解决这个问题,作者选择了预测组合中的最后n个token,而不是从头开始预测整个句子。
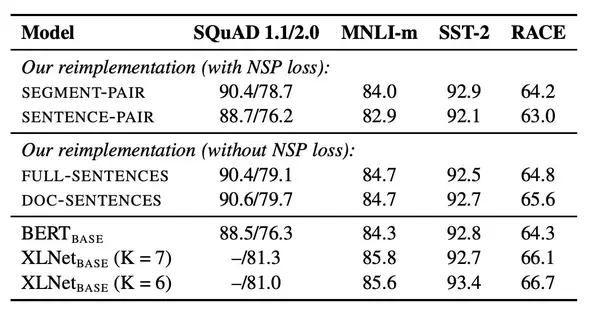
2.3 RoBERTa
$XLNet$ 预训练模型在 20 项任务上全面碾压曾有 “最强 NLP 预训练模型” 之称的 $BERT$,可谓风光无限,吸足了眼球。然而,现实是残酷的,$XLNet$ 的王座没坐太久,Facebook就公布了一个基于 $BERT$ 开发的加强版预训练模型 RoBERTa—— 在 GLUE、SQuAD 和 RACE 三个排行榜上全部实现了最先进的结果!不得不让人感慨nlp领域真是强者辈出啊。
RoBERTa 的名称来 “Robustly optimized BERT approach“,强力优化的 BERT 方法,名字起的很唬人,其实创新点并没有太多,基本就是$BERT$上面的老一套:
- 对模型进行更长时间、更大批量、更多数据的训练
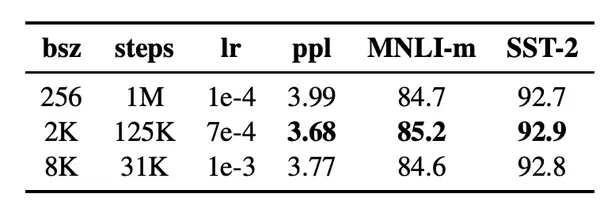
- 删除下一句预测的目标
在原始的 BERT 预训练过程中,模型观察到两个连接的文档片段,它们要么是从相同的文档连续采样 (p = 0.5),要么是从不同的文档采样。除了 masked language modeling 目标外,该模型还通过辅助下一句预测 (NSP) 损失训练模型来预测观察到的文档片段是来自相同还是不同的文档。
NSP 损失被认为是训练原始 BERT 模型的一个重要因素。Devlin 等人 (2019) 观察到,去除 NSP 会损害性能,QNLI、MNLI 和 SQuAD 的性能都显著下降。然而,最近的一些工作对 NSP 损失的必要性提出了质疑,因而,作者设计了几组对比实验来验证:
(1)Segment+NSP:bert style (2)Sentence pair+NSP:使用两个连续的句子+NSP。用更大的batch size (3)Full-sentences:如果输入的最大长度为512,那么就是尽量选择512长度的连续句子。如果跨document了,就在中间加上一个特殊分隔符。无NSP。实验使用了这个,因为能够固定batch size的大小。 (4)Doc-sentences:和full-sentences一样,但是不跨document。无NSP。最优。
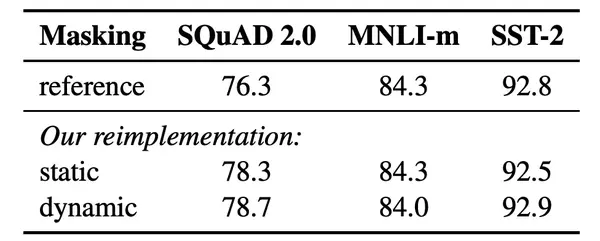
- 对较长序列进行训练
- 动态改变应用于训练数据的 masking 模式。
每一次将训练example喂给模型的时候,才进行随机mask,而不是在预处理阶段直接处理好文本以后就不在变化了。
- 修改了超参数:将adam的
参数从0.999改为0.98
- Text Encoding:采用更大的byte-level的BPE词典
从上面总结中可以看出,RoBERTa并没有在模型结构方面作出创新,通篇读下来,基本是针对各种工程细节进行了考究,也符合起名字:$Robustly\ optimized \ BERT \ approach$。不过,仅仅是在一些工程细节上做出一番精心打磨,就取得了超越$XlNet$的效果,足以说明,$BERT$的原始架构已经足够强大,后续的模型改进的提升幅度不太可能会再取得如$BERT$横空出世的时候的那种炸裂的效果。
2.4 T5
综述类文章,处处体现着Google的高(cai)大(da)逼(qi)格(cu),详细探讨了transformers训练过程中各种因素的影响,模型无创新。
2.5 Electra
虽然目前$MLM$大行其道,不过,由于预测的只是样本中的部分token,比如$BERT$只预测了15%的token,那么代价就是substantial compute cost。针对这些问题,一种新的模型-electra横空出世,先看其效果:

再看其模型细节,作者称之为$replaced\ token\ detection$的$pre-training$技术:
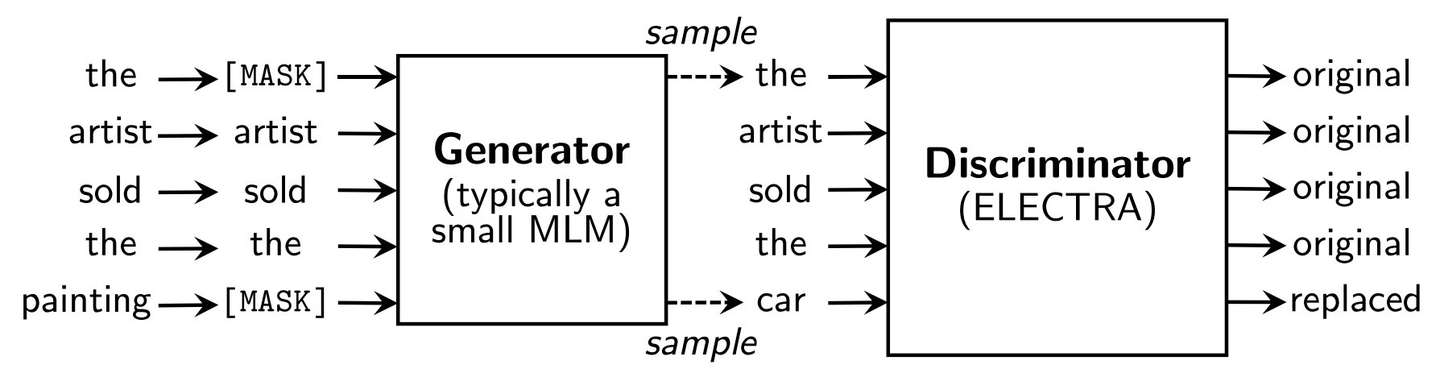
乍看这个图,CVer一定虎躯一震,大喊一声:“这不是GAN么?”。不好意思,这虽然看着像GAN,却不是GAN,现在拆分一下其训练步骤:
- 对于一个给定的输入序列,随机用[MASK]替换某些tokens
- generator为所有masked tokens预测原始tokens
- discriminator的输入为将输入序列中的[MASK]替换为generator的预测tokens
- 对序列中的每个token,discriminator预测其是原始的token还是经过generator替换过的token
从这个流程可以看出,其训练与GAN有类似之处,不过,generator训练的目的不是为了尝试欺骗discriminator,所以其并不是GAN。
generator模型被训练成预测被masked的token的原始token,而discriminator模型被训练成预测给定corrupted序列的哪些token被替换。这意味着在对每个token进行预测时,可以计算所有输入token的discriminator损失。而在MLM中,模型损失只在被masked的标记上计算。这便两种方法之间的关键区别,也是ELECTRA效率更高的主要原因。
另外注意,generator只在pre-training的时候使用,所以只有discriminator会被用于下游任务中。
2.6 ALBERT
BERT的引入为NLP打开了一扇新的窗户,不过后来逐渐有走上邪路的趋势,一般无脑堆数据和模型都能带来不小的提升。不过,随着数据与算力竞赛的加剧,很多算力与数据较弱的研究机构逐渐被淘汰,无法跟得上模型的进展,榜单上的名单也就在那几家大厂商之间轮流转,这显然不利于NLP的多样发展的,所以后来,越来越多的目光着眼于如何降低模型对于算力的要求,ALBERT(A Lite BERT)便是其中之一。
ALBERT主要在三个方面做出了改变:
- Factorized embedding parameterization
在BERT,XlNet,RoBERTa等方法中,embedding size E是与hidden size H绑定在一起的,而这个做法从建模与实用角度来说是非最优的,因为从建模角度来说,word embeddings是为了学习context independent representations(此处存疑),而hidden embeddings则是为了学习context dependent representations,将二者解耦可以更高效的利用模型参数;从实用角度来说,二者保持一致的话会导致他们同增同减,增大hidden size的话很容易导致vocabulary size变得很大,这也会导致embedding过于稀疏,不利于学习。
针对这个问题,ALBERT通过对embedding parameters进行分解,得到两个小矩阵来缓解。具体做法就是使用较小的E(E«H),然后通过矩阵变换到H,这时候参数数目就可以从$O(V \times H)$降低到$O(V\times E+E \times H)$,当$E«H$的时候,参数下降是非常明显的,而$H$包含的信息显然应该是多过$E$的,所以$E«H$也是非常合理的。
- Cross-layer parameter sharing
之前的transformer是多层block的堆积,每个block的参数都是独立的,因而参数数目正比于层数,之前也有过参数共享的研究,不过只共享了部分参数,而ALBERT则做的比较极端,他提出了共享全部的参数,这样的话参数数目便独立于堆叠的block的层数,这时候的ALBERT其实只相当于是只有一个block的堆叠。
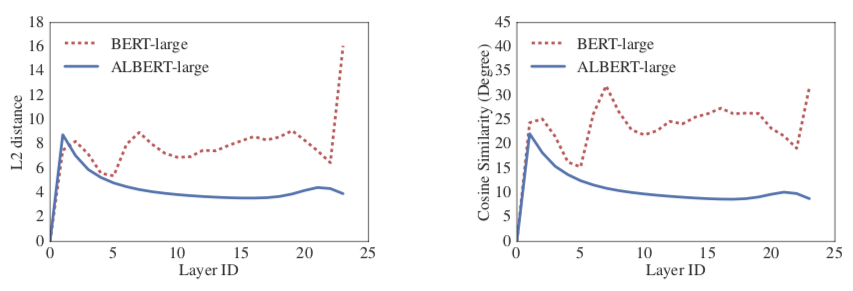
- Inter-sentence coherence loss
这是用来替换NSP loss的一种新的loss,原来NSP就是来预测下一个句子的,也就是一个句子是不是另一个句子的下一个句子。这个任务的问题出在训练数据上面,正例就是用的一个文档里面连续的两句话,但是负例使用的是不同文档里面的两句话。这就导致这个任务包含了主题预测在里面,而主题预测又要比两句话连续性的预测简单太多。新的方法使用了sentence-order prediction(SOP), 正例的构建和NSP是一样的,不过负例则是将两句话反过来。实验的结果也证明这种方式要比之前好很多。
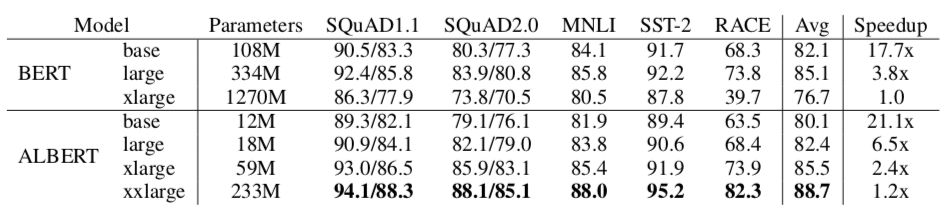
从结果来看,ALBERT确实相比于BERT参数量大大减少了,不过其训练速度却降了下来,BERT-large相比于ALBERT-xxlarge快了2倍(3.8x->1.2x),而且注意,$ALBERT $只是减少了计算量,毕竟参数少了,不过其inference速度并没有改善多少,毕竟还是很多block的堆叠,所以后续还有继续优化的空间。
3.展望
BERT的面世将nlp带到了一个新的高度,它的出现甚至让有的人感叹nlp领域已经没什么可做的了,当然,这是玩笑。毕竟,BERT离真正步入我的生活还有许多工作要做,包括速度与数据等等方面,后来BERT-like的模型发展的如火如荼,也让我们能亲身感受到nlp的魅力。不过,模型的发展毕竟是非常快的,我们可能也没有精力去追踪每一个新模型,但如果真正掌握了模型的细节,你会发展现在的新模型并没有架构上的革新之处,有的只是修修补补,所以,打好基础吧少年!