模型蒸馏探索(Bert)
1. 蒸馏是什么?
所谓的蒸馏,指的是从大模型(通常称为teacher model)中学习小模型(通常称为student model)。何以用这个名字呢?在化学中,蒸馏是一个有效的分离沸点不同的组分的方法,大致步骤是先升温使低沸点的组分汽化,然后降温冷凝,达到分离出目标物质的目的。那么,从大模型中,通过一定的技术手段,将原模型中的知识提取出来,这个过程很类似于物质分离,所以将其称为是蒸馏。
2. 蒸馏方法
2.1 Logit Distillation
深度学习巨头Hinton提出,是一篇开创性的工作。
其改进是针对softmax进行的改进:
\[q_{i}=\frac {exp(z_{i}/T)}{\sum_{j}exp(z_{j}/T)}\]其中的T是temperature,为设定的超参数。
最终的loss为:
\[L=(1-\alpha)cross\_entrophy(y,p)+\alpha *cross\_entrophy(q,p)T^{2} \\ y:真实label\\p:student\ model预测结果\\q:teacher model预测结果 \\ \alpha:蒸馏loss权重\]这个改进的motivation有一下几点:
- softmax函数自身对数据分布敏感
对于相同的logits,当采用不同的temperature的时候,softmax之后的分布变化较大,温度越大,分布越平缓,结果的区分度越低,相当于增大了学习的难度,以后做inference的时候,temperature=1,分类结果会得到较好的提升。
- soft prediction本身带有额外的信息
soft prediction代表teacher model对不同类别的识别概率,这个概率分布本身就带有一定的信息的,比如预测轿车的时候,识别为垃圾车和胡萝卜的概率可能都比较低,但是识别为垃圾车的概率显然要比识别为胡萝卜更高,这个信息说明垃圾车本身相比于胡萝卜与轿车的相关性更高。
这里有人可能会好奇,为何需要先训练teacher model,然后再蒸馏到student model上面?为何不能直接训练student model?
要注意的是,蒸馏的核心思想是好的模型不是为了拟合训练数据,而是学习如何泛化到新的数据,所以蒸馏到目的是为了让学生模型学习到教师模型的泛化能力。单纯训练学生模型的话,因为模型比较简单,所以训练难度也更大,其训练出的模型的泛化能力大概率也不如教师模型强大。
另外注意,模型蒸馏是一种思想,理解了这篇文章的思想,可以泛化到后续的许多模型中去,因为蒸馏的使用其实本质就是各种loss function的设计。
2.2 Distilled BiLSTM
这篇文章在性能方面完全不存在竞争力,在transformer满天飞的年代,其蒸馏的结果仅仅是获得了ELMo级别的性能,不过,这篇文章最大的亮点是,在ELMo性能级别下,其使用的参数少了大约100倍,推理时间少了15倍,这对于资源敏感类任务来说可谓是一个巨大的诱惑。
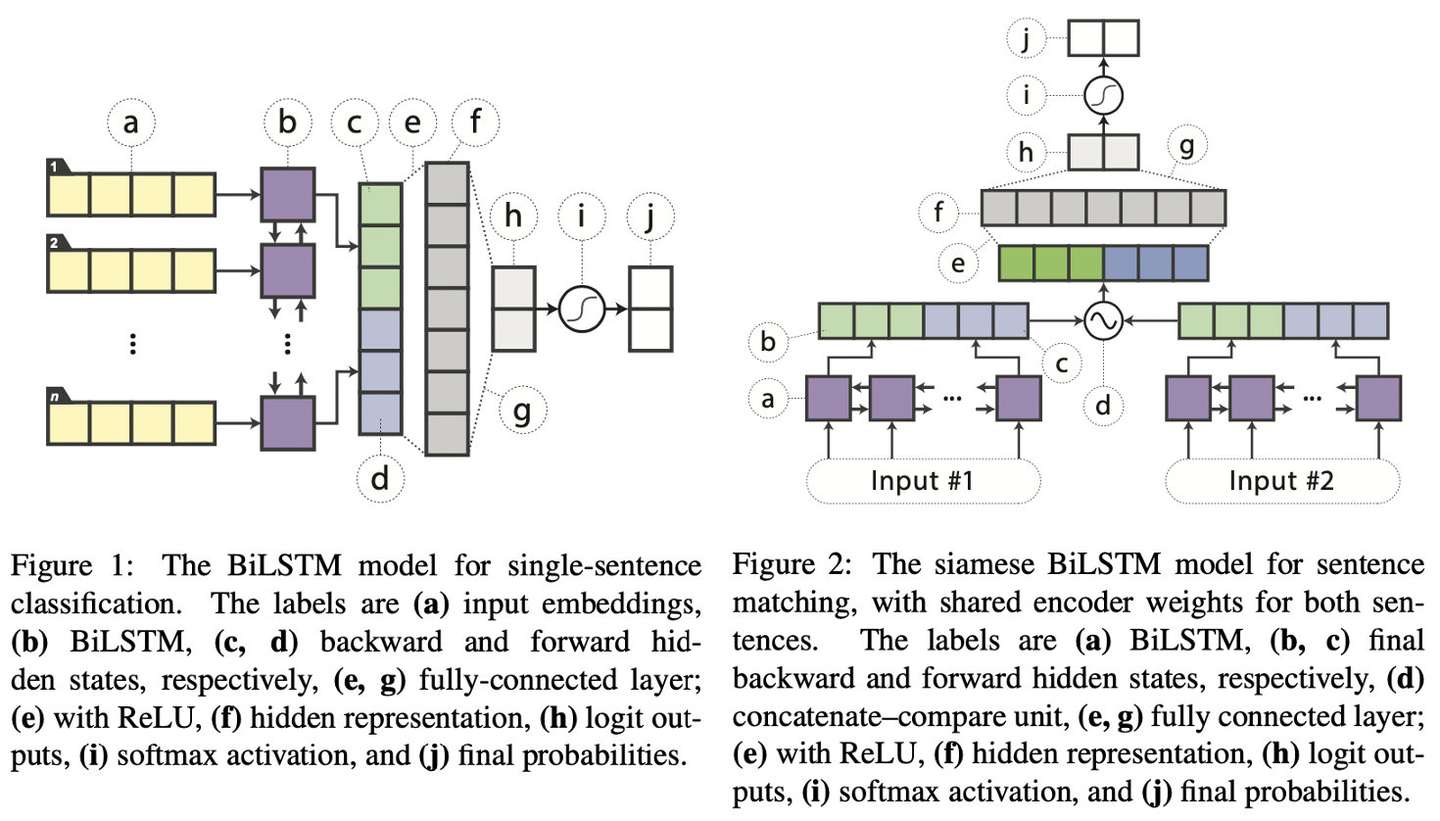
注意FIgure 2中的d操作,对于两个句子向量,其操作为:$f(h_{s1},h_{s2})=[h_{s1},h_{s2},h_{s1}\odot h_{s2},|h_{s1}-h_{s2}|],\odot$代表 elementwise multiplication.
上损失函数:
\[\begin{equation}\begin{aligned}Loss &= \alpha L_{CE}+(1-\alpha)L_{distill}\\&=-\alpha \sum_{i} t_{i}logy_{i}^{S}-(1-\alpha)||z^{B}-z^{S}||_{2}^{2}\end{aligned}\end{equation}\]其中,$z^{B},z^{S}$分别为teacher和student的logits,即预测值,$t_{i}$为真实one-hot类别向量$t$为第i个元素,对于无标签元素,$t_{i}=1\ if\ i=argmaxy^{B}\ else\ 0$ 。
论文中作者还提出了一些nlp领域的数据增强技术,可以看原文了解一下。
2.3 DistilBERT
这篇文章没啥难理解的地方,记录一下就行了。
效果:模型尺寸降低40%,保留97%的泛化能力,提升了60%的速度。
模型:teacher model为标准的Bert,student model为layers=teacher model layers/2的Bert,从teacher model的layers中每隔2层取一层初始化student model的layer。
损失函数:公式(1)的cross entropy和masked language modeling loss,外加两模型的首层的隐状态的cos loss。
2.4 BERT-PKD
PKD(patient knowledge distill),其teacher model为标准BERT,而student model也是BERT,不过其堆叠的层数要少于teacher。先上图为敬:

从架构图可以看出,相比于直接学习最终的输出,PKD方法还教导student model学习中间层的输出,last方法的先验假设是认为teacher model的top layers包含最丰富的信息以便指导student model,而skip的先验假设则是认为teacher model的lower layers也包含了需要被蒸馏的重要信息,从作者的结果来看,PKD-Skip 效果slightly better,作者认为PKD-Skip抓住了老师网络不同层的多样性信息。而PKD-Last抓住的更多相对来说同质化信息,因为集中在了最后几层。
对于BERT类模型来说,由于其输入序列长度比较大,如果学习所有的tokens,不仅computationally expensive, 也可能introduce noise,又考虑到BERT的预测是只针对“[CLS]” token的最后一层输出,所以如果student model可以获得teacher model的[CLS]的表达能力,那么它就有了teacher model的泛化能力,所以直接学习[CLS]。
损失函数设计:
\[L_{PKD}=(1-\alpha)L_{CE}^{s}+\alpha L_{DS}+\beta L_{PT}\quad 上标s代表student\ model\]CE loss:
\[L_{CE}^{s}=-\sum_{i\in |N|}\sum_{c\in C}[I(y_{i}=c)\cdot logP^{s}(y_{i}=c|x_{i};\theta^{s})]\quad C代表labels,N代表样本数目\]DS loss:
\[L_{DS}=-\sum_{i\in |N|}\sum_{c\in C}[P^{t}(y_{i}=c|x_{i};\hat {\theta^{t}})\cdot logP^{s}(y_{i}=c|x_{i};\theta^{s})]\quad 上标t代表teacher \ model\]PT MSE loss:
\[L_{PT}=\sum_{i=1}^{N}\sum_{j=1}^{M}||\frac{h_{i,j}^{s}}{||h_{i,j}^{s}||_{2}}-\frac{h_{i,I_{pt(j)}}^{t}}{||h_{i,I_{pt(j)}}^{t}||_{2}}||_{2}^{2}\quad I_{pt}(j)为s\ model第i层相对应的t\ model层\]另外,这篇paper还做了一个很有意思的实验,那就是一个更好的teacher model对于更好的蒸馏是否有效果。

结论:
- #1和#2对比发现,更好的teacher model并没有带来更好的效果。
- #1和#3对比可发现,student model使用更好的model,哪怕使用更好的teacher model,效果依然变差,作者推测是压缩比(teacher model 参数量:student model参数量)更高,student model获取的信息变少了。
- #2和#3的对比可发现,即便使用相同的teacher model,更好的student model依然表现更差,这里作者解释是初始化的缘故,因为理想的情况是对于$BERT_{6}[Base]$或者$BERT_{6}(Large)$应该是从头训练,不过由于资源受限,所以这俩模型都是使用$Bert_{12}$或者$Bert_{24}$的前六层参数初始化,而他们前面的六层参数可能不够捕获高层特征导致结果有差异。
看一下这个架构,可以发现teacher model是循序渐进,一步一步教导student model去学习,而不是仅仅给出最后的答案就行了,这大概就是为何被称为patient了,这篇论文在2.3的基础上展示了中间层用于蒸馏的作用。
2.5 TinyBert
上面介绍的几种蒸馏算法,实现了从embedding,中间层,到分类层的蒸馏,不过他们还只是停留在transformer block之外,没有从transformer本身出发去蒸馏,而tinybert则提出了深入到transformer内部去做蒸馏的新方法(Transformer distillation)。最终效果在 GLUE 上达到了与 BERT 相当(下降 3 个百分点)的效果,同时模型大小只有 BERT 的 13.3%(BERT 是 TinyBERT 的 7.5 倍),Inference 的速度是 BERT 的 9.4 倍。此外,TinyBERT 还显著优于当前的 SOTA 基准方法(BERT-PKD),但参数仅为为后者的 28%,推理时间仅为后者的 31%。

student model有N层,teacher model有M层,从M层中选择N层用于蒸馏,损失函数设计:
- embedding layer输出
- transformer层的hidden states和 attention matrices($A=\frac{QK^{T}}{\sqrt{d_{k}}}$)
\[L_{attn}=\frac{1}{h}\sum_{i=1}^{h}MSE(A_{i}^{s},A_{i}^{t})\quad h为attention\ heads数目\] \[L_{hidn}=MSE(H^{s}W_{h},H^{t})\quad W_{h}是为了防止H^{s}与H^{t}维度不一致\]加入attention based loss的灵感来自于Clark等人的发现,即attention weights包含了substantial linguistic knowledge,这份知识很有必要transfer到student model中。
- 预测层输出的logits
另外,这篇论文还提出了一种novel two stages 学习方式:

老师网络是没有经过在具体任务进行过微调的Bert网络,然后在大规模无监督数据集上,进行Transformer distillation,当然这里的蒸馏就没有预测输出层的蒸馏。再针对具体任务进行蒸馏,老师网络是一个微调好的Bert,学生网络使用general learning之后的tinybert,对老师网络进行TD蒸馏。
一些结论:


对不同蒸馏模块(GD:General Distillation、TD:Task-specific Distillation和DA:Data Augmentation)和不同类型蒸馏层(Embd: Embedding layer、Pred:Prediction layer和Trm:Transformer layer)分别进行的消融实验,结果如上表所示。实验结果表明:(1)论文提出的通用性蒸馏、任务相关性蒸馏以及数据增强对TinyBERT学习都有显著的帮助,其中任务相关蒸馏和数据增强模块在四个数据集上有持平的影响,同时两者相比通用性蒸馏模块影响更大;(2)Transformer层的蒸馏是TinyBERT学习的关键,基于注意力矩阵的蒸馏相比隐藏层的蒸馏更加重要。
2.6 MobileBert
motivation:To the best of our knowl-edge, there is not yet any work for building a task-agnostic lightweight pre-trained model, that is, a model that can be generically fine-tuned on different downstream NLP tasks as the original BERT does. In this paper, we propose MobileBERT to fill this gap.
想实现任务无关的蒸馏Bert看起来似乎挺容易,只要用一个大Bert去指导小的Bert直到收敛为止即可,不过,实际做的时候却会有很大的性能损失,毕竟其表达能力不够。那么,如果解决这个问题呢?mobilebert给出了自己的答案,其精妙就是上图,通过IB-BERT来蒸馏。mobilebert在保留24层的情况下,减少了4.3倍的参数,速度提升5.5倍,在GLUE上平均只比BERT-base低了0.6个点,效果好于TinyBERT和DistillBERT。
相比于以往的蒸馏算法,MobileBert有两个方面的不同:
- 只在pre-training阶段做蒸馏
- 不同于以往的蒸馏算法努力从深度方面蒸馏Bert,MobileBert则是尝试在宽度方面蒸馏Bert
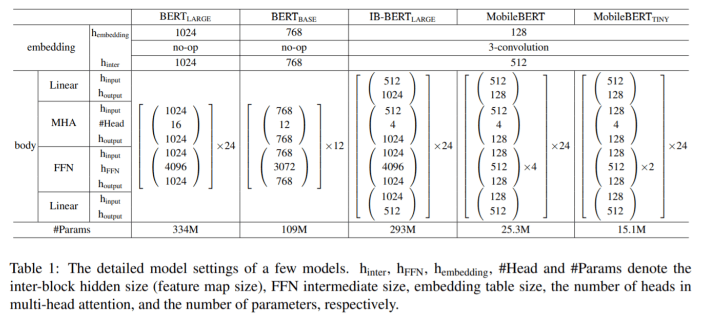

模型细节如上图,MobileBert与$BERT_{large}$同等深度,不过每一个block更小,不同于标准的Bert,IB-BERT和MobileBert均有Linear层来做维度变换。这里引入IB-BERT的原因是直接训练MobileBert很难,所以先训练IB-BERT,再做蒸馏。
Bottleneck的原理是在transformer的输入输出各加入一个线性层,实现维度的缩放。对于教师模型,embedding的维度是512,进入transformer后扩大为1024,而学生模型则是从512缩小至128,使得参数量骤减。采用了 bottleneck 机制的 IB-BERT 也存在问题,bottleneck 机制会打破原有的 MHA(Multi Head Attention)和 FFN(Feed Forward Network)之间的平衡,原始 bert 中的两部分的功能不同,参数比大概为 1:2。采用了 bottleneck 机制会导致 MHA 中的参数更多,所以作者在这里采用了一个堆叠 FFN 的方法,增加 FFN 的参数,Table1 中也能看出。
为了让模型更快,作者发现最耗时间的是 Layer-Norm 和 gelu,将这两个部分进行替换。把需要均值和方差的 Layer-Norm 替换为 NoNorm ($NoNorm(h)=\gamma \odot h+\beta$)的线性操作,把 gelu 替换为 ReLU,word-embedding 降为 128,然后用一个 3 核卷积操作提高到 512。
损失函数设计(Figure 1有标注):
- feature map transfer(FMT)
由于在 BERT 中的每一层 transformer 仅获取前一层的输出作为输入,layer-wise 的知识转移中最重要的是每层都应尽可能靠近 teacher。特别是两模型每层 feature-map 之间的均方误差,T为序列长度,N为feature map size,上标为层索引:
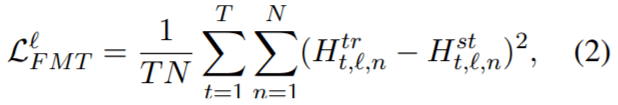
-
attention transfer(AT)
注意机制极大地提高了 NLP 的性能,并且成为 transformer 中至关重要的组成部分。作者使用从经过优化的 teacher 那里得到 self_attention map,帮助训练 MobileBERT。作者计算了 MobileBERT 和 IB-BERT 之间的自注意力之间的 KL 散度,A为attention heads的数目:
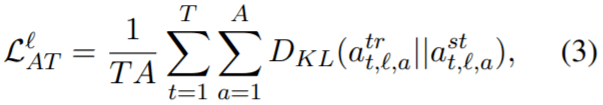
-
Pre-training Distillation (PD)
还可以使用原始的掩码语言模型(MLM),下一句预测(NSP)和新的 MLM 知识蒸馏(KD)的线性组合作为预训练蒸馏损失。
训练策略,下面作者讨论了三种策略:
- Auxiliary Knowledge Transfer
这种策略下,认为中间层的knowledge transfer是用于knowledge distillation的辅助任务。使用单个loss,这个loss是所有层的knowledge transfer losses和pre-training distillation loss的线形组合。
- Joint Knowledge Transfer
IB-BERT 的intermediate知识(即attention map和feature map)可能不是 MobileBERT 学生的最佳解决方案。因此,作者建议将这两个 Loss 分开。首先在 MobileBERT 上训练所有 layer-wise knowledge transfer losses,然后通过pre-training distillation进一步训练它。
- Progressive Knowledge Transfer
作者也担心如果 MobileBERT 无法完美模仿 IB-BERT,底层可能会影响更高的层次的知识转移。因此,作者建议逐步培训知识转移的每一层。渐进式知识转移分为 L 个阶段,其中 L 是层数。
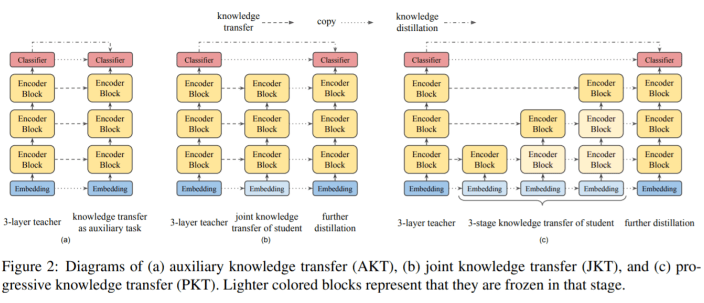
从图可知,对于策略2和3,在layer-wise knowledge transfer阶段对于开始的embedding 层和最后的分类层没有knowledge transfer;对于3,在训练第i层的时候,会冻结它下面的所有层的可训练参数,在实践中,在训练i层的时候,并没有完全冻结下层参数,而是使用一个小的学习率去微调下层参数。
最后的结论是逐层蒸馏效果最好,但差距最大才0.5个点,性价比有些低了。
2.7 MiniLm
来自于微软的一篇论文,论文中声称“In particular, it retains more than 99% accuracy on SQuAD 2.0 and several GLUE benchmark tasks using 50% of the Transformer parameters and computations of the teacher model.”
看完上面那么多的蒸馏方法,可以发现已有的工作基本从内到外将Bert-like model和transformer蒸馏个遍,看起来似乎没啥可以蒸馏的了,不过,这篇文章确实另辟蹊跷,从最基础的self-attention modules入手作出了一些工作,具体点说,蒸馏teacher model的最后的transformer层的self-attention module,这种做法相比于以前的分层蒸馏方法而言,不再需要做teacher model和student model层之间的映射,而且student model的结构也更有弹性。

老规矩,直接看loss函数是如何设计的:
\[L=L_{AT}+L_{VR}\]self-attention distribution transfer(KL-divergence):
\[L_{AT}=\frac{1}{A_{h}|x|}\sum_{a=1}^{A_{h}}\sum_{t=1}^{|x|}D_{KL}(A_{L,a,t}^{T}||A_{m,a,t}^{S})\\|x|:序列长度\\A_{h}:attention \ heads数目\\L:teacher\ model层数\\M:student\ model层数\\A_{L}^{T}:teacher\ model最后一层transformer的attention\ distributions,通过queries和keys的scaled\ dot-product计算\\A_{M}^{S}:student\ model最后一层transformer的attention\ distributions,通过queries和keys的scaled\ dot-product计算\]self-attention value-relation transfer:
\[VR_{L,a}^{T}=softmax(\frac{V_{L,a}^{T}V_{L,a}^{T_{T}}}{\sqrt {d_{k}}})\\VR_{M,a}^{S}=softmax(\frac{V_{M,a}^{S}V_{M,a}^{S_{T}}}{\sqrt{d_{k}}})\\L_{VR}=\frac{1}{A_{h}|x|}\sum_{a=1}^{A_{h}}\sum_{t=1}^{|x|}D_{KL}(VR_{L,a,t}^{T}||VR_{M,a,t}^{S})\\V_{L,a}^{T}\in R^{|x|\times d_{k}},V_{M,a}^{S}\in R^{|x|\times d_{k}}:teacher和student\ model最后一个transformer层的一个attention\ head的values\\VR_{L}^{T}\in R^{A_{h}\times |x| \times |x|},VR_{M}^{S}\in R^{A_{h}\times |x| \times |x|}:teacher和student\ model最后一个transformer层的value-relation\]可以发现,MiniLM的总体实现是比较简单的,它只使用了最后的transformer层,通过引入values的relation,学生网络可以更深刻的去模仿教师网络的行为,这个思路是以前别人没做过的。另外,values-relations和attention distribution都采用了scaled dot-product,还带来了另外一个好处,那就是教师网络和学生网络可以使用不同的hidden dimensions,这样的话学生网络可以更有弹性,可根据需要选择不同的hidden dimensions,从而避免了引入额外参数而改变了学生网络的表达能力。
这篇论文还使用了一个teacher assistant机制来进一步提升了效果,可以读原文了解一下。

对比一下MiniLM和其他模型。MOBILEBERT提出使用一个特殊设计的inverted bottleneck模型,它的模型大小与$BERT_{LARGE}$相同,来作为教师。其他方法利用$BERT_{BASE}$进行实验。对于用于提炼的知识,MiniLM引入了自注意力模块中values之间的scaled dot-product作为新的知识,来深度模仿教师的自注意力行为。TinyBERT和MOBILEBERT将教师的知识层层传递给学生。MOBILEBERT假设学生的层数与教师相同。 TinyBERT采用统一的策略来确定层映射。DistillBERT用教师的参数初始化学生,因此仍然需要选择教师模型的层。MiniLM提炼出教师最后一个Transformer层的自注意力知识,使得学生的层数灵活,减轻了寻找最佳层映射的工作量.DistillBERT和MOBILEBERT的学生隐藏大小被要求与其教师相同。 TinyBERT使用参数矩阵来转换学生的隐藏状态。使用值关系允许我们的学生使用任意的隐藏大小,而不需要引入额外的参数。
最后,好不好是看结果说话的,看一下该模型的结果:
将$BERT_{base}$版作为teacher,将其蒸馏为6层,768维的student模型,各个蒸馏模型在SQuAD 2.0和GLUE上的实验结果如 上Table 2所示,从实验结果可以看出,在多数任务上MiniLM都优于DistillBERT和TinyBERT。特别是在SQuAD2.0数据集和CoLA数据集上,MiniLM分别比最先进的模型高出3.0个F1值和5.0个accuracy。不同模型大小的推理时间对比可以参考下面的Table 4。
总的来说,MiniLM是一种十分方便实现的蒸馏算法,非常推荐去尝试。
2.8 Bert-of-Theseus
来自于微软的文章,这篇文章思路比较清奇,因为它不像其他的蒸馏算法一样通过各种loss来实现知识迁移,而是通过渐进式模块替换来实现蒸馏效果。作者论文中声称,这个模型的灵感来自于“ship of theseus”,即一艘船的每个部件逐渐被替换直到所有的部件都被替换一遍。Bert-of-Theseus的方法类似于ship of theseus,他通过用更少参数的模块替换BERT(论文中称为predecessor,对应于teacher model)的模块从而逐步训练得到蒸馏后的模型(论文中称successor,对应于student model)。
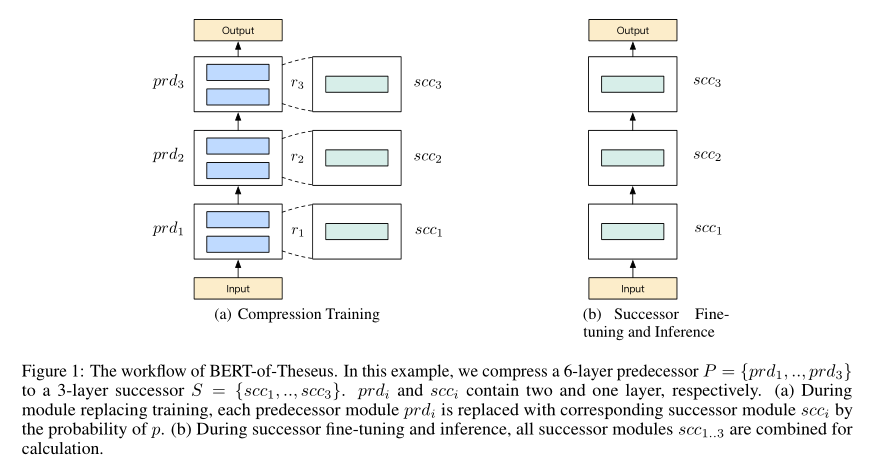
这篇文章的实现比较简单,从图中基本可以看懂其过程。
假设前驱模型𝑃和后继模型𝑆都含有𝑛个模块,即$𝑃={𝑝𝑟𝑑_{1},…,𝑝𝑟𝑑_{𝑛}},𝑆={𝑠𝑐𝑐_{1},…,𝑠𝑐𝑐_{𝑛}}$,其中$𝑠𝑐𝑐_{i}$是用来替换$𝑝𝑟𝑑_{i}$的。假设第𝑖个模块输入为$y_{i}$,前驱模型的前向过程可以表示为:
\[𝑦_{𝑖+1}=𝑝𝑟𝑑_{𝑖}(𝑦_{𝑖})\]压缩时,对于第𝑖+1个模块,$𝑟_{i+1}$是一个独立的从伯努利分布采样的变量,即以概率𝑝取值为1,以概率$1−p$取值为0:
\[𝑟_{𝑖+1}∼Bernoulli(p)\]那么第𝑖+1个模块的输出变成
\[𝑦_{𝑖+1}=𝑟_{𝑖+1}⊙𝑠𝑐𝑐_{𝑖}(𝑦_{𝑖})+(1−𝑟_{𝑖+1})⊙𝑝𝑟𝑑_{𝑖}(𝑦_{𝑖})\]其中⊙表示逐元素乘操作,$𝑟_{i+1}$∈{0,1}。通过这种方式,前驱模块和后继模块在训练时一起运作。并且由于引入了类似Dropout的随机性,也相当于为训练过程添加了正则化。
训练的损失函数就是任务特定的损失函数,比如分类问题中的交叉熵损失函数.
在反向传播时,所有前驱模块的权重将会被冻结,只有后继模块参数会被更新。对于前驱模型的嵌入层和输出层除了进行权重冻结外,在训练阶段还会直接当作后继模块。通过这种方式,可以在前驱模块和后继模块之间计算梯度,从而可以进行更深层次的交互。
上面训练以后,由于每个step训练时,只会有部分不同的 module参与到训练中,所有的
并没有整合到一起参与到任务训练中。因此需要添加一个post-training过程,将所有
重新组合成完整的transformer:
并沿用前驱模块的embedding layer和output layer(因为之前训练时这些权重参数都是freeze的,可以直接拿来用),在相同的训练数据和下游任务场景下进行finetune。
此外,作者还提出了个渐进替换策略来提高性能,在这种策略中,替换概率随着时间增加:
\[p_d = \min (1,\theta(t))=\min (1, kt+b)\]其中𝑡是训练步数,𝑘>0是系数,𝑏是基本的替换概率。非渐进式替换和渐进式替换的替换概率如下图(a),(b)所示:
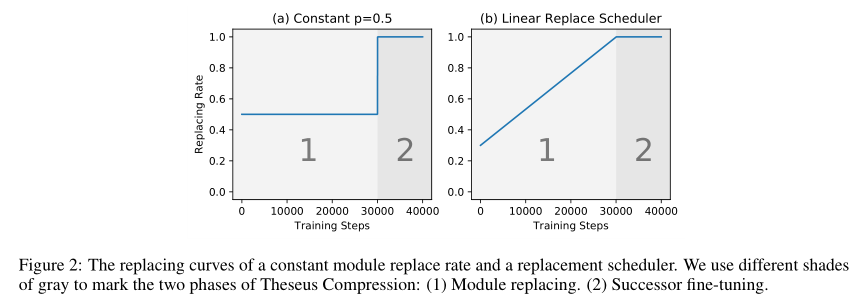
通过渐进式替换策略,之前独立的训练和微调过程可以统一起来,形成一个端到端,从易到难的学习过程。在初始阶段,前驱模块作用仍然较大,使得模型损失能够平滑下降。之后,替换概率增大,逐渐过渡到了后继模块微调阶段。
最后,看其性能:


从其性能来看,还是非常不错的,论文声称BERT模型在保证98%性能的基础上比原模型快1.94倍,不过其训练略微繁琐,不过好处是只使用一个损失函数和一个超参数就能够进行模型压缩,省去了各种loss的组合的开销,也是一个非常不错的方法。
3.conclusion
模型蒸馏作为模型压缩的一种手段,是一种比较有效的方法来降低模型规模。它的优点在于非常灵活,可以很方便的从一个模型迁移到另一个模型;不过,它也有自己的缺点,那就是它还需要额外的训练,这就对数据和时间提出了一定的要求,另外就是student model也需要经过精心的设计才能实现比较好的蒸馏。