文本生成方法梳理
nlp领域个人还是非常喜欢文本生成这个方向,现在大致梳理一下文本生成的相关问题。
1. 文本生成方案
目前业界的文本生成方案主要有三种:
(1)规则模板。典型的技术就是AIML语言。这种回复实际上需要人为设定规则模板,对用户输入进行回复。
- 优点:1、实现简单,无需大量标注数据;2、回复效果可控、稳定。
- 不足:1、如果需要回复大量问题,则需要人工设定大量模板,人力工作量大;2、使用规则模板生成的回复较为单一,多样性低。
(2)生成模型。主要用encoder-decoder结构生成回复。典型技术是Seq2Seq
、transformer。
- 优点:无需规则,能自动从已有对话文本中学习如何生成文本。
- 不足:1、生成效果不可控,训练好的模型更像是一个“黑盒”,也无法干预模型的生成效果;2、倾向生成万能回复,如“好的”、“哈哈”等,所以多样性与相关性低。
(3)检索模型。利用文本检索与排序技术从问答库中挑选合适的回复。
- 优点:由于数据来源于已经生成好的回复,或是从已抓取的数据得到的回复,所以语句通顺性高,万能回复少;
- 不足:1.不能生成新的回复文本,只能从问答库中得到文本进行回复;2.当检索或排序时,可能只停留在表面的语义相关性,难以捕捉真实含义。
从业界应用广度来说,应该是1,3更广,2的范围较为狭窄。不过对于该领域的爱好者而言,明显是2更具备吸引力,因为2可深挖的点远远多于其他两者,所以本文也只关注2这个方向。
2. 生成模型相关方向
2.1 Seq2Seq
对于AIer来说,这肯定是个如雷贯耳,手到擒来的名字了,该模型不多做介绍,只说一下单纯的Seq2Seq用于文本生成存在的问题:
-
负面情感的回复
-
疑问句式的回复
-
回复的多样性较低
-
回复一致性低:比如用户说“我喜欢旅游”,bot回复“我不喜欢,我喜欢”,这就存在问题。
-
上下文逻辑冲突;背景有关的一些信息,比如年龄其实不可控;
-
安全回复居多,对话过程显得很无聊。
-
训练时用到的数据都是人类的对话语料,往往充斥着已知和未知的背景信息,使得对话成为一个”一对多”的问题,比如问年龄和聊天气,回答包括不同的人针对同样的问题产生的不同的回复。
-
但是神经网络无论多复杂,它始终是一个一一映射的函数。
-
最大似然只能学到所有语料的共通点,所有背景,独特语境都可能被模型认为是噪音,这样会让模型去学习那些最简单出现频率高的句子
,比如”是的”之类的回复,我们称之为安全回复。
-
-
对话语料的局限性
- 对话语料只是冰山的一角,实际上对话语料中潜藏着很多个人属性、生活常识、知识背景、价值观/态度、对话场景、情绪装填、意图等信息,这些潜藏的信息没有出现在语料,建模它们是十分困难的。
除此之外,Seq2Seq在多轮对话方面建模也不是很友好,目前已有的一些研究虽然基于多轮对话做了尝试,不过模型层面还是比较复杂的,训练的话鲁棒性也不是那么好。
改进策略
2.1.1 融合关键输入信息
1. copy机制,从输入中拷贝结果到输出,可以有效缓解OOV问题
代表paper:Get To The Point: Summarization with Pointer-Generator Networks
模型结构:

此结构思路相对简单,只要熟悉Bahdanau attention机制基本可以很轻松的看懂论文的内容:
Bahdanau attention机制: \(e_i^t = v^T tanh(W_{h}h_i + W_{s}s_t + b_{attn})\)
\[a^t = softmax(e^t)\] \[h_{t}^{*} = \sum_{i}{a_i^t h_i} \quad 上下文向量\] \[P_{vocab} = softmax(V'(V[s_t, h_t^*] + b) + b')\ 词表概率分布,[s_t,h_t^*]代表concat\] \[P(w) = P_{vocab}(w)\] \[loss_{t} = -logP(w_t^*)\quad t时刻生成目标词w_{t}^{*}\] \[loss = \frac{1}{T} \sum_{t=0}^{T}loss_t\]其中:
t:decoder时间步,$h_{i}$:encoder时间步i处隐状态,$s_{t}$:decoder t时刻状态,v,$W_{h}$,$W_{s}$,$b_{attn}$,$V$,$V^{‘}$,$b$,$b^{‘}$都是可学习参数。
pointer generator network机制:
首先这里注意,pointer generator network会扩充单词表形成一个更大的单词表–扩充单词表(将原文当中的单词也加入到其中), \(p_{gen} = \sigma(w_{h^*}^T h_t^* + w_s^Ts_t + w_x^Tx_t + b_{ptr})\quad x_{t}:t时刻decoder输入\)
\[P(w) = p_{gen}P_{vocab}(w) + (1 - p_{gen}) \sum_{i:w_i=w} a_i^t\]其中:
$w_{h^}^{T},w_s^T,w_x^T,b_{ptr}$为可学习参数,$\sigma$为sigmoid*函数。
$p_{gen}$被用作一个两种决策的软连接: 通过$P_{vocab}$从词表中生成一个词, 还是从输入序列的注意力分布中$a_{i}^{t}$进行采样得到一个词。可以看到解码器一个词的输出概率有其是否拷贝是否生成的概率和决定。当一个词不出现在常规的单词表上时 𝑃𝑣𝑜𝑐𝑎𝑏(𝑤)为0,当该词不出现在源文档中∑𝑖:𝑤𝑖=𝑤为0。
2. 覆盖概率机制,致力于解决生成重复内容的问题
代表paper:Modeling Coverage for Neural Machine Translation
Get To The Point: Summarization with Pointer-Generator Networks
主要针对场景是机器翻译,在“seq2seq+attention”框架下的翻译过程中,翻译当前词汇的“注意力”与翻译在此之前的词汇的“注意力”是独立的,当前的操作不能从之前的翻译中获取alignment相关的信息,这样就导致了“过度翻译”和“漏翻译”的问题。此覆盖率模型中,作者保留了一个 覆盖率向量(coverage vector) $c^{t}$ ,具体实现上,就是将先前时间步的注意力权重加到一起得到所谓的覆盖向量 $c^{t}$(𝑐𝑜𝑣𝑒𝑟𝑎𝑔𝑒 𝑣𝑒𝑐𝑡𝑜𝑟),用先前的注意力权重决策来影响当前注意力权重的决策,这样就避免在同一位置重复,从而避免重复生成文本(注意,下面的公式来自于pointer generator network): \(c^t = \sum_{t'=0}^{t-1}a^{t'}\)
\[e_i^t = v^T tanh(W_{h}h_i + W_{s}s_t + w_{c}c_i^t + b_{attn})\] \[covloss_{t} = \sum_{i}min(a_i^t, c_i^t)\] \[loss_t = -logP(w_t^*) + \lambda \sum_{i}min(a_i^t, c_i^t)\]覆盖率损失(coverage loss) 来惩罚将注意力重复放在同一区域的行为.
3.主题控制
致力于解决的问题:普通的seq2seq生成的内容,其实没有办法把控生成的语义信息。通过增加关键词信息,用关键词去影响生成回复的语义(主题)
- 使用关键词作为硬约束,即关键词一定出现在生成文本中
模型架构:
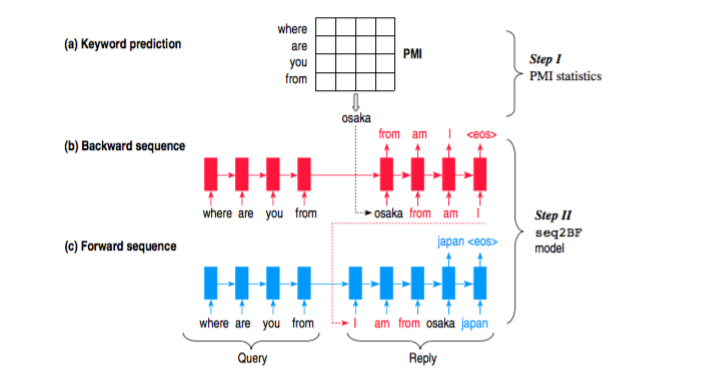
从架构图可以看出,模型包括两个步骤:
(1)从reply中选择PMI( pointwise mutual information)最高的word作为keyword,这个word被限定为名词,该词可以认为是reply的topic,该词也会作为后续seq2seq模型的第一个输入word,用来引入topic信息。

(2)如步骤1所说,keyword是作为decoder的第一个输入token,这时候传统的seq2seq就不符合要求了,因而这里提出了修改版的seq2seq,被称为“sequence to backward and forward sequences”—-Seq2BF。
由于keyword是reply中的word,因而以keyword为分界线,reply即被分割为前后两部分,对于前半部分,使用backward从keyword前面的一个词一直预测到第一个词,也就是反序预测;对于后半部分,则使用forward从keyword后面一个单词一直预测到末尾,具体可以从图上看出。
优点:
keyword来做topic的思路是一个很好的思路,会让算法生成的reply更加有营养,这个在单轮的应用背景下可以取得不错的结果。
缺点:
不适用于多轮回话,多轮回话应该考虑上下文信息,而不是只考虑当前的reply;keyword限制过大,可作为topic的并不一定是名词,可能还会是短语,也可能是语义层面上的topic;预测的单词不准,或者在对话中出现较少时,上下句可能衔接不够流畅
- 使用关键词作为软约束,即关键词不一定出现在生成文本中
代表paper:Towards Implicit Content-Introducing for Generative Short-Text Conversation Systems
模型架构:

循环单元HGFU(Hierarchical Gated Fusion Unit):

$C_{w}$:cue word,选择方法同3.1中的Seq2BF。
该模型设计了cue word gru单元,将关键词信息加入到每一步的状态更新。利用设计的fusion unit结构融合普通的GRU和cue word gru单元。
注意此模型与Seq2BF的区别,该模型是把cue word的信息融合进了每次的循环,而不是像Seq2BF一样使用将cue word插入到forward阶段保证了cue word一定出现。
优点:
将cue word加入到了每一步的循环,有利于信息的充分利用
缺点:
软约束导致cue word并不一定出现了生成文本,导致漏翻;仍然只适用于短文本;cue word选择不好,结果也可能不流畅
- 多关键词搭配覆盖机制约束
代表paper:Topic-to-Essay Generation with Neural Networks
模型架构:文章中提出了三种结构,这里只介绍最好效果的结构(MTA-LSTM)。
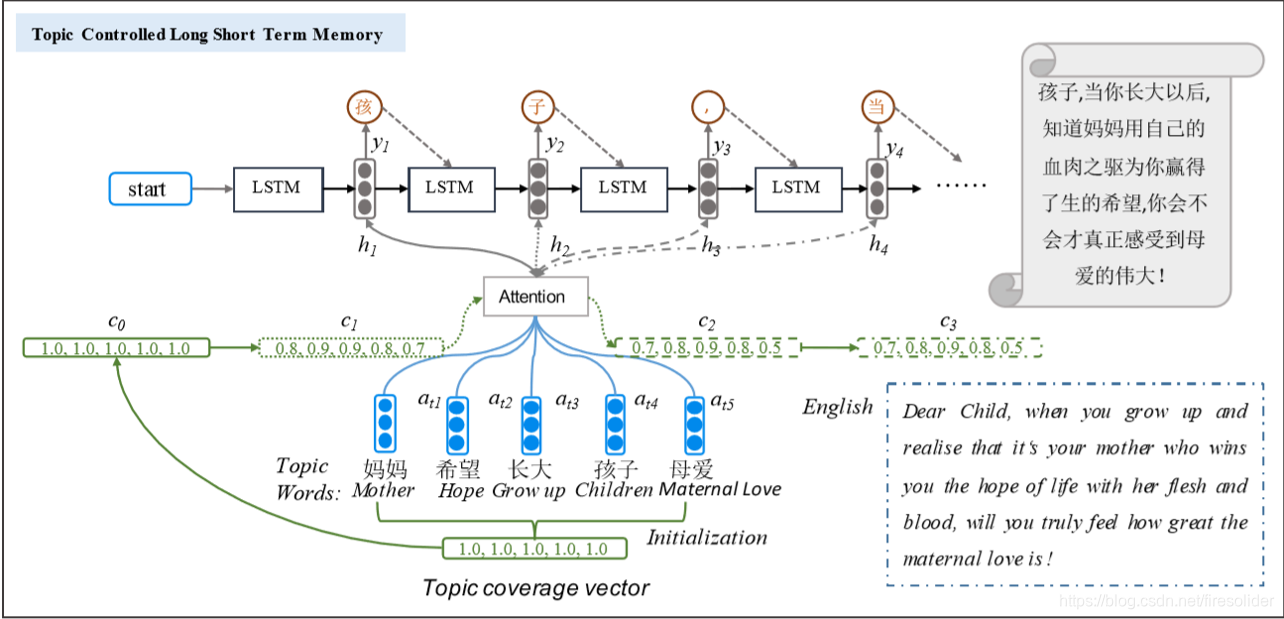
符号定义:$k: topic词数目,topic_{i}:第i个topic词的embedding,g_{t,j}:在t时刻,topic_{j}的attention\ score,C:coverage向量$
初始:$C_{0}=[1.0,1.0…] 长度为k$,代表为编码的信息量为1 \(g_{t,j}=C_{t-1,j}v_{a}^{T}tanh(W_{a}h_{t-1}+U_{a}topic_{j})\ v_{a},W_{a},U_{a}为可学习参数\)
\[\alpha_{tj}=\frac {exp(g_{tj})} {\sum_{i=1}^{k}exp(g_{ti})}\] \[T_{t}=\sum_{j=1}^{k}\alpha_{tj}topic_{j}\] \[C_{t,j}=C_{t-1, j}-\frac {1} {\phi_{j}}\alpha_{t,j}\quad \alpha_{t,j}时刻t时topic_{j}的attention\ score\] \[\phi_{j}=N\cdot \sigma(U_{f}[T_{1},T_{2},...T_{k}])\quad U_{f}\in R^{kd_{w}},此处T_{i}代表topic\ embedding\]下一个词的预测概率: \(P(y_{t}|y_{t-1},T_{t},C_{t})=softmax(g(h_{t}))\ g(\cdot):linear \ function\)
1. Generating Sentences from a Continuous Space
发表于2015年,是VAE用来文本生成领域的经典之作。作者提出使用VAE的motivation是:RNN虽然通过evolving distributed state representation打破了独立性假设,使得它能够建模复杂序列,但是RNNLM预测方式为逐词预测,这个特性导致其不能很好的形成高层次的语义特征表示(主题、语义、句法)。
|  |
作为祖师级的文章,其idea还是非常可圈可点的,另外论文中提出的解决KL vanish的trick也值得关注一下。